Двоичная система счисления
Системы счисления
quote
Система счисления - это способ записи (представления) чисел.
Вообще, существует много разных систем счисления. Римская, вавилонская, древнеегипетская... За историю человечества было придумано много способов для реализации такой, казалось бы, простой и базовой потребности - для записи чисел.


Каждый день мы используем десятичную систему счисления.
Позиционные и непозиционные системы счисления.
В зависимости от того, имеет ли значимость порядок цифр в записи числа, системы бывают позиционными и непозиционными.
Например, десятичная система - позиционная, так как когда мы с её помощью записываем числа, порядок цифр имеет значение. Записи 199 и 991 будут обозначать два разных числа.
Римская же система счисления - непозиционная (с некоторыми оговорками). Записи MCX, CMX и XCM будут обозначать одно и то же число (1110).
Запись числа в десятичной системе счисления
Итак, как уже было сказано, самая общеиспользуемая система счисления - это десятичная.
Называется она десятичной потому, что для записи чисел с её помощью используется десять знаков: 0123456789.
Что же означает запись числа в десятичной счисления? Давайте попробуем "разложить" некоторые числа:
\( 123 = 1 * 100 + 2 * 10 + 3 \)
\( 7491 = 7 * 1000 + 4 * 100 + 9 * 10 + 1 \)
Думаю, не трудно заметить, что здесь прослеживается некая закономерность.
Её можно записать математически:
\( x_1x_2x_3...x_n = x_1 * 10^{n-1} + x_2 * 10^{n-2} + .. + x_n * 10^0 \)
...где:
- \( x_1x_2x_3...x_n \) - какое-то число в десятичной системе из n чисел
- \( x_1, x_2, ..., x_n \) - цифры этого числа
Число 10 в данном случае будет называться основанием системы счисления - это число доступных нам цифр для записи чисел в этой системе. Поэтому в формуле и фигурирует число 10.
Переносим правила записи числа на двоичную систему
Как несложно догадаться, двоичная (бинарная) система счисления - это позиционная система, в которой для записи чисел используются только два символа: 1 и 0.
Для этой системы будут действовать те же самые правила, что и для десятичной, но только в полученной формуле число 10 придётся заменить на число 2.
note
Чтобы дальше не путаться между системами счисления, мы будем использовать
следующую запись:
\( 12345_{10} \)
Где число снизу обозначает разрядность системы счисления.
Попробуем разложить бинарное число по той же схеме:
\( 100111_2 = 1 * 2^5 + 0 * 2^4 + 0 * 2^3 + 1 * 2^2 + 1 * 2^1 + 1 * 2^0 \)
Если посчитаем полученное значение, у нас получится \( 32 + 4 + 2 + 1 = 39_{10}\)
Поздравляю! Мы научились раскладывать число в двоичной системе счисления. В принципе, с другими системами счисления всё будет точно так же, но число 2 нужно будет заменить на основание используемой системы счисления.
Перевод из десятичной системы в двоичную
Итак, давайте немного порефлексируем по поводу того, как мы перевели число из двоичной системы счисления в десятичную.
По сути, что мы сделали - это представили число как сумму разных степеней двойки. Вот и всё.
Получается, если мы поймём, из каких степеней двойки "складывается" десятичное число, мы легко сможем записать его в двоичном виде.
Итак, предлагаю свой достаточно простой алгоритм перевода числа из десятичной системы в двоичную.
- Сначала, как бы это дико не звучало, нам нужно запомнить первые 10 степеней двойки (10 - это я написал навскидку, это не конкретное правило).
Возможно, в начале это сложно будет сделать, поэтому можно просто переписать себе куда-то таблицу с этими степенями:
| Степень | Значение |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
| 5 | 32 |
| 6 | 64 |
| 7 | 128 |
| 8 | 256 |
| 9 | 512 |
| 10 | 1024 |
- Смотрим на наше десятичное число, и анализируем, какая самая большая степень двойки может в него поместиться. Например, для числа 63 это будет 5-я степень \( 2:5 = 32\)
- Записываем число как
степень двойки + остаток - Повторяем все описанные шаги для остатка, пока исходное число не будет полностью записано в виде суммы степеней двоек
В принципе, всё довольно просто. Давайте рассмотрим это на примере.
Примеры
Перевод числа из десятичной системы в двоичную
Начальное число: 1083
- Самая большая влезающая степень двойки - 1024.
- Записываем 1083 как
1024 + 59. Далее анализируем число 59. - В 59 максимум может поместиться только 32.
- Записываем 59 как
32 + 27. Далее анализируем число 27. - В 27 влезает только 16.
- Записываем 27 как
16 + 11. Далее анализируем 11. - В 11 максимум влезает 8.
- Записываем 11 как
8 + 3. Далее анализируем 3 - Ну, с тройкой всё уже понятно - её можно записать просто как
2 + 1 - Теперь собираем по кусочкам все полученные степени двойки и получаем следующую запись: \( 1083 = 1024 + 32 + 16 + 8 + 2 + 1 = 2^10 + 2^5 + 2^4 + 2^3 + 2^1 + 2^0\)
Нетрудно догадаться, что искомой записью числа в двоичной системе счисления будет:
10000111011
Перевод числа из двоичной системы в десятичную
Начальное число: 11100101110110.
Длина числа - 14. Поэтому просто по формуле распиываем нужное число в десятичной системе счисления:
\( 1 * 2^{13} + 1 * 2^{12} + 1 * 2^{11} + 1 * 2^8 + 1 * 2^6 + 1 * 2^5 + 1 * 2^4 + 1 * 2^2 + 1 * 2^1 = \)
\( = 8192 + 4096 + 2048 + 256 + 64 + 32 + 16 + 4 + 2 = 14710 \)
Источники
- https://habr.com/ru/articles/124395/
Задания к уроку "Двоичная система счисления"
1. Перевод в двоичную систему счисления
Переведи следующие числа из десятичной в двоичную систему счисления
- 0
- 1
- 3
- 12
- 57
- 148
- 673
- 227
- 64
- 126
2. Перевод в десятичную систему счисления
Переведи следующие числа из двоичной в десятичную систему счисления
1010001010101000111010101110100110001101110111101010101111100011011111
3. Бонусная секция: прочие системы счисления
- Переведи в троичную систему число \(165_{10}\)
- Переведи число \(1011_{2}\) в семиричную систему счисления
- Переведи число \(753_{8}\) в девятиричную систему счисления
- Переведи число \(333_{4}\) в пятиричную систему счисления
Чем отличаются языки программирования
Прежде чем начать изучать какой-то из языков программирования, нужно очень чётко представлять себе, а почему вы выбрали учить именно его.
На моём опыте и в школе и в универе особо не заостряли на этом моменте внимания, и как итог, многие люди считают, что языки отличаются только тем, что "один быстрее другого", или "на одном языке писать код легче, чем на другом".
Основные различия ЯП
Разное предназначение
Перед разработкой нового языка программирования, авторы в первую очередь закладывают какую-то цель, какую-то потребность, которую должен восполнять новый создаваемый инструмент.
Например:
- C был задуман как язык с удобным синтаксисом, на котором возможно писать низкоуровневые эффективные приложения, и первое применение получил в написании операционной системы (ОС) Unix.
- Golang был придуман как простой язык с низким порогом входа, для быстрого создания маленьких и быстрых программ.
- С++ был создан как продолжение языка C с реализацией новых концепций программирования (о чём мы более подробно поговорим в других статьях).
- Ada был создан как очень безопасный и надёжный язык для работы на военных объектах и самолётах
- и так далее...
Причём стоит различать конкретные области, в которых используется ЯП, и его предназначение.
Например, С++ зачастую используют для создания игр - но это не была его изначальная цель (на момент появления C++ ещё не был создан тетрис). В этом случае характеристики языка просто очень удачно подходят для решения заданной задачи.
Предназначение языка программирования выражается на практике в его реализации, о чём мы поговорим далее.
Исполнение программ на ЯП
Существуют разные способы "запуска" кода на каком-то языке программирования. Подробнее об этом говорится здесь.
Но если коротко, код, написанный на разных языках программирования, запускается и работает по-разному.
Какой-то код собирается в готовую программу (например, .exe), какой-то нет.
Для программ на одном языке может использоваться сборщик мусора (что это такое, рассмотрим в другой статье), для программ на другом языке нет.
Это может значительно влиять как на производительность программ, так и на простоту их переноса с одной системы на другую.
Идиомы и парадигмы
Люди занимаются программированием (...в том или ином виде) уже больше сотни лет, и за это время у разработчиков выработалось огромное число разных подходов и основных техник написания кода, планирования архитектуры программы, и так далее.
Если говорить обобщённо, то какие-то из этих подходов и техник можно назвать идиомами, а какие-то парадигмами. Конкретно об этих понятиях мы будем говорить далее.
Яркими примерами парадигм программирования являются Объектно-ориентированное программирование (ООП), Функциональное программирование (ФП) и Аспектно-ориентированное программирование.
Как пример самых простых идиом же можно привести RAII, Обмен значениями и Инкремент.
Реализованные концепции
В языках программирования существуют разные инструменты, которые облегчают работу над какими-то задачами, или просто позволяют подстроить процесс написания программы под себя.
В разных языках реализовываются разные концепции. Например, в C++ есть перегрузка операторов, шаблонное программирование, указатели, и так далее.
Низкоуровневость
Разные языки на разных уровнях взаимодействуют с железом компьютера.
Компьютеру, чтобы, например, вывести на экран окно графического приложения (например, того же калькулятора), нужно сделать очень много вычислений: просчитать координаты всех пикселей на экране, которые нужно вывести, закрасить их каким-то цветом, и т.д. и т.п.
И на каких-то языках можно программировать очень близко к тем самым низкоуровневым командам, которые на самом деле выполняются на машине, а на каких-то нет.
В том же питоне, например, то же самое окно можно инициализировать буквально за пару строчек кода.
Низкоуровневость языка влияет на его скорость: чем ближе мы с помощью ЯП общаемся с компьютером, тем точнее и быстрее будут программы на этом языке (очень грубо говоря).
Но у низкоуровневости есть и свои минусы: из-за того, что мы близко общаемся с целевым компьютером, переносить приложения на таких ЯП с одной машины на другую может быть достаточно проблематично. Также увеличивается время и сложность разработки в целом.
Дизайнерские решения
Это те отличия, которые и без всякой теоретической базы вы заметите при переходе от одного языка программирования на другой.
В основном, это конечно же разный синтаксис, разные правила оформления кода, разные структуры и расширения файлов с исходным кодом и так далее.
Косвенные различия ЯП
Итак, всё то, что мы обсуждали выше - это основные различия языков программирования, то есть различия, которые в язык были заложены самими создателями языка. Далее же мы посмотрим на более бытовые, и из-за этого чуть более актуальные, раличия между ЯП.
Сферы применения
Об этом мы частично говорили в пункте про разное предназначение.
Какие-то языки используют в основном для написания игр и серверных программ, какие-то - для веб-разработки, какие-то для написания драйверов и программирования микроконтроллеров, какие-то языки используют для научных расчётов, и т.д.
Зачастую люди выбирают ЯП именно из-за конкретной сферы разработки, с которой они хотели бы работать.
Порог входа
Какие-то языки программирования легко начинать изучать с нуля, а на какие-то необходимо потратить не один десяток часов, чтобы начать хотя бы примерно понимать, что там вообще происходит.
Как пример ЯП с низким порогом входа, можно вспомнить Python и Golang (у Golang низкий порог входа вообще является чуть ли не одним из главных преимуществ).
Как пример ЯП с высоким порогом входа упомяну:
- NASM, TASM и прочие диалекты ассемблера
- C
- Rust
- С++
- ...
Актуальность
Возможно, учить какой-нибудь Lisp, COBOL или Eiffel очень интересно, но в реальном мире эти языки не особо то и применяются, и работу со знанием этих технологий будет найти очень тяжело.
Но актуальность языка выражается не только в количестве рабочих мест: это отражается и на самом процессе разработки. В устаревшем ЯП скорее всего не будут поддерживаться современные технологии и концепции, реализованные в новых языках, для него будет мало современных библиотек, фреймворков и SDK (что это такое подробнее обсудим позже), из-за чего писать программы на нём будет уже не так удобно.
Уровень з/п
Пункт, который косвенно связан с предыдущим. Но здесь скорее играет роль спрос и предложение на специалистов в конкретной области.
Ведь питон, например, сейчас очень востребован, и применяется в практически любой крупной компании. Но одновременно с этим людей, которые ищут работу для начинающего разработчика на этом языке тоже огромное множество: из-за огромной популярности языка, низкого порога входа и бесчисленных курсов.
Языковые процессоры
Языковой процессор - это механизм, который отвечает за перевод инструкций из кода на языке программирования (ЯП) в машинный код, который будет исполняться на конкретной машине.
Далее мы рассмотрим, какие они бывают, и как они примерно работают.
Почему это важно
Обычно, в схожих обучающих материалах ничего не говорят про процесс сборки готовой программы и языковые процессоры. Авторы ограничиваются тем, что просто показывают, в какой последовательности нужно нажимать кнопки в среде разработки (IDE), чтобы программа "заработала".
Я считаю, что перед первой строчкой написанного когда, человек должен чётко понимать, как записанные на ЯП инструкции будут выполнены на компьютере.
В пользу своей точки зрения, приведу несколько аргументов, почему первый подход вреден:
- Окей, вот ты зазубрил, куда надо нажимать в IDE, чтобы запустить проект. А что если в процессе вылезет какая-то ошибка? Как ты будешь с этим работать? Остаётся единственный вариант - либо звать препода, либо выполнять туториалы из гугла наугад, надеясь что всё заработает. Подход не очень классный. В лучшем случае ты на основе проб и ошибок поймёшь то, что мог бы понять заранее намного быстрее.
- Понимание процесса генерации исполняемого файла необходимо для понимания того, как работает даже самая простая
Hello Worldпрограмма на С++. И мы это дальше увидим. - Рано или поздно, когда потребуется собрать сложный проект из нескольких модулей, вам придётся разбираться с тем, как работает сборка и компиляция.
Компилятор
Компилятор - это специальная программа, которая переводит код на ЯП в машинный код, который потом уже исполняется на компьютере.
То есть, при помощи компилятора мы из исходного кода получаем готовую программу - например, на Windows это будет готовый .exe файл.
Процесс генерации машинного кода из исходного назвается компиляцией, а языки, код на которых обрабатывается компилятором, называются компилируемыми.
Алгоритм работы компилятора упрощённо можно представить так:
flowchart LR
A["main.cpp"] --> B["Компилятор"]
B --> C["main.exe"]
flowchart LR
D("Пользователь") -->|Входные данные| E("main.exe")
E -->|"Выходные данные"| D
Когда мы компилируем код в готовую программу, мы имеем возможность полностью просканировать содержимое программы до её сборки и запуска, и, соответственно, найти ошибки в коде.
Также само выполнение программы будет быстрее, чем в случае с интерпретатором, так как все инструкции из исходного кода были преобразованы и оптимизированы во время компиляции.
Но, у сборки программ при помощи компилятора есть и свои недостатки, как, например, сильная зависимость от целевой платформы и долгое время компиляции.
Транслятор
Транслятор работает примерно так же, как и компилятор, за тем лишь исключением, что транслятор переводит исходный текст программы не в машинный код, а в код на другом ЯП.
С помощью транслятора, при создании языкового прцоессора для какого-то языка, нам не нужно с нуля писать абсолютно всю логику переноса исходного кода в машинный - часть ответственности за этот процесс можно делегировать готовому компилятору.
Также использование транслятора может помочь при создании процессора для своего небольшого языка, как, например, Seed7, или эзотерических языков по типу Brainfuck, Piet и прочих.
Интерпретатор
Существует также и другой подход к исполнению инструкций исходного кода, который применяется, например, в питоне.
В отличие от компилятора, интерпретатор, вместо получения готовой программы, непосредственно выполняет операции, указанные в исходной программе, над входными данными, которые предоставляет программе пользователь.
Языки, код на которых выполняется при помощи интерпретатора, назваются интерпретируемыми.
Алгорит работы интерпретатора упрощённо можно представить так:
flowchart LR A["main.py"] --> B["Интерпретатор"] C["Входные данные"] --> B B --> D["Выходные данные"]
Код на интерпретируемых языках программирования зачастую лучше портируется между системами, + не требует дополнительных затрат времени на компиляцию.
Но интерпретируемые программы из-за свой архитектуры, как правило, работают менее эффективно, чем заранее скомпилированные программы, + мы не можем заранее оптимизировать или проанализировать исходный код так же эффективно, как при использовании компилятора.
Смешанные системы
На самом же деле, достаточно редко для какого-то ЯП используется либо только компилятор, либо только интерпретатор. Обычно это смешанные системы.
Хороший пример - Java. Хоть с этим языком есть много тонкостей, примерно выполнение программы на Java можно представить себе так:
flowchart TD A["Исходная программа"] --> B["Транслятор"] B --> C["Промежуточная программа"] C --> D["Виртуальная машина Java"] D --> E["Выходные данные"] F["Входные данные"] --> D
Ещё стоит отметить, что даже те языковые процессоры, которые, казалось бы, используют только компилятор, на самом деле выглядят чуть сложнее.
Например, тот же C++, который является компилируемым языком, на самом деле обрабатывается примерно следующим образом:
flowchart TD
A("Исходная программа") --> B["Препроцессор"]
B -->|Модифицированная исходная программа| C["Компилятор"]
C -->|Целевая ассемблерная программа| D["Ассемблер"]
D -->|Перемещаемый машинный код| E["Компоновщик/загрузчик"]
G("Библиотечные файлы") --> E
H("Перемещаемые объектные файлы") --> E
E --> F["Целевой машинный код"]
classDef file fill:grey;
class A file
class G file
class H file
Подробнее будем рассматривать процесс обработки кода на C++ в другой статье.
Источники
- Компиляторы: принципы, технологии и инструментарий - Альфред Ахо и др., 2 изд.
Компиляция и сборка программ на C++ [в разработке]
При написании программ на С++ критически важно понимать, как из исходного кода генерируется готовая программа.
C++ - это компилируемый язык, что значит, что программы на C++ компилируются в готовый исполняемый файл. Но на самом деле, в процессе генерации исполняемого файла учавствует не только один компилятор.
Давайте рассмотрим процесс обработки исходного кода на С++ подробнее.
Общая схема
flowchart TD
A("Исходная программа") --> B["Препроцессор"]
B -->|Модифицированная исходная программа| C["Компилятор"]
C -->|Целевая ассемблерная программа| D["Ассемблер"]
D -->|Перемещаемый машинный код| E["Компоновщик/загрузчик"]
G("Библиотечные файлы") --> E
H("Перемещаемые объектные файлы") --> E
E --> F["Целевой машинный код"]
classDef file fill:grey;
class A file
class G file
class H file
На этой схеме есть много новых понятий - препроцессор, компоновщик, ассемблер. Рассмотрим каждое из них подробнее.
Первая программа на C++
Обычно изучение любого языка программирования начинается с написания программы, которая выводит на экран строчку "Hello World!". Поступим так же.
Итак, та самая программа:
#include <iostream>
int main()
{
std::cout << "Hello World!\n";
}
В принципе, что здесь происходит, можно понять и чисто наугад, но давайте всё же разберём подробнее.
- Выполнение любой программы на C++ начинается с выполнения функции
main. Можно сказать, что это такая "точка входа" в нашу программу.
В противовес этому решению в C++, на питоне например выполнение программы начинается прямо с первой строки файла. Но зачастую на питоне можно встретить следующие штуки:
def main():
print("Hello world")
if __name__ == "__main__":
main()
Так достаточно часто пишут в реальных популярных проектах. Как пример, который первым пришёл в голову : проект Sherlock, у которого на гитхабе ~53000 звёзд.
По сути, это можно назвать мимикрией под язык C++, в котором выполнение программы начинается с выполнения функции main (ну и, в принципе, им и заканчивается).
-
Перед функцией
mainмы написали#include <iostream>- так мы попросили препроцессор включить в наш файл весь код, записанный в библиотекеiostream. Нам это нужно, чтобы вывести текст в консоль. -
Что же происходит в самой функции
main? В ней у нас прописана только одна строчка:std::cout << "Hello world!\n";. Здесь мы помещаем в поток стандартного вывода строчку "Hello World!" с переносом на новую строчку.
Последний пункт, скорее всего, вызывает у вас больше всего вопросов. Разберём, что здесь происходит, подробнее.
- В этой строчке у нас записана конечная операуия. Прибавить число к переменной, вывести строчку на экран, объявить новую переменную, вызвать функцию, ... - всё это какие-то операции. В конце каждой операции в C++ нужно ставить
;. Это - очередное дизайнерское решение, отделяющее C++ от других языков, таких как, например, питон. - Что такое поток стандартного вывода? Вообще, поток - это какой-то канал, через который можно отправлять куда-то информацию, или получать её оттуда. Можно представить себе это как конвейер на производстве, где на бесконечно крутящуюся ленту ставят коробки. Поток стандартного вывода - это такой же "конвейер", который поставляет определённую нами информацию в стандартный вывод (или, проще говоря, в терминал).
В нашем коде мы "положили на конвейер"
std::coutстрочку "Hello World", и конвейер доставил эту строчку в терминал. Так же бывают строковые потоки, или файловые. В этих случаях "конвейер" будет доставлять данные в переменнуюstring(в строчку), или в файл. - Помещаем мы данные в поток при помощи оператора угловых скобок -
<<. Этот оператор принимает два аргумента (один записывается слева, а другой справа). Первый аргумент - это поток, куда мы будем помещать информацию, а второй - сама "информация" (имя переменной, класс, вызов функции, ...), которую нам надо передать. Если же вызвать оператор<<для двух целых чисел (например,1 << 2), произойдёт бинарный сдвиг. Подробнее о различных операторах будем говорить в темах "основные операции C++" и "перегрузка операторов". - В конце мы записали символ
\n. Это - специальный символ, который обозначает переход на новую строку в терминале. Когда компьютер видит, что мы хотим вывести\n, он понимает, что мы хотим перейти на следующую строчку.
Почему переход на новую строку так странно записывается? Почему нельзя было просто нажать в коде Enter?
Дело в том, что \n - это специальная управляющая последовательность, или же escape sequence для терминала.
Когда мы работаем с терминалом в нашей программе (да и в любой другой), мы работаем по сути с 2D-полем, на котором можем рисовать свои символы. На этом поле у нас есть курсор, который определяет конкретную позицию на поле, на котором мы остановились.
Итак. Вот мы вывели на экран "Hello world".
Hello world!
@ <- так я изобразил курсор. Он указывает на поле после `!`
И дальше мы хотим перейти на следующую строчку. Вспомним, что мы находимся на 2D-поле. И во фразе "поместить на поле символ Enter" нет никакого смысла! Потому что Enter - это управляющая кнопка на клавиатуре, которая не представляет никакой символ. Символы - это буквы, цифры, знаки препинания и т.д.
Чтобы перейти на следующую строчку, нам на самом деле нужно переместить курсор на начало следующей строки.
Представьте себе курсор как исполнителя-робота из Кумира, или черепаху из ПервоЛого: курсору, чтобы перейти по 2D-полю на начало следующей строки, надо:
- Опуститься на одну "клетку" вниз - на следующую строку
Hello world!
@
- Переместиться влево до начала текущей строки
Hello world!
@
Таким образом, мы перешли на новую строку. Да, оказывается, даже переход на новую строчку в терминале не такой простой, как кажется!
...стоит понимать, что \n - это не единственная управляющая последовательность. Среди основных других можно встретить:
\t- вывод таба (Tab) на экран\r- перемещение курсора в начало текущей строки\',\",\\- не совсем управляющие последовательности, но просто способ вывести символы',"и\на экран.
Таким образом, именно из-за таких особенностей работы в терминале, чтобы перейти в терминале на новую строчку, нужно писать \n. Но на самом деле есть и другие причины. Например:
- если бы мы реально в коде нажимали
Enter, он бы выглядел мягко говоря неряшливо. Что было бы, если бы мы хотели вывести, скажем, 5 переходов на новую строку? - по правилам синтаксиса C++, строчки у нас должны записываться на одной линии исходного кода (с некоторыми оговорками). У нас же в файле есть и форматирование, и табы, и отступы. Как тогда нам надо бы было с этим всем работать? Просто забить на все предыдущие табы и всё форматирование, и просто поверх фигачить строчки? Это бы тогда выглядело как-то так:
int main()
{
std::cout << "Hello World!
This is multiline text
I wanted to print
";
}
И выглядело бы ужасно.
На самом деле, в C++ существуют raw string literals, которые помогают записывать примерно в такой форме текст в исходных файлах без управляющих последовательностей. Если интересно, что это, можешь загуглить. Но примерно с ними строчки можно записывать так:
int main()
{
std::cout <<
R"###(
Hello world!
This is multiline text
I wanted to print.
)###";
}
Зачем нам вообще здесь переходить на новую строку? На самом деле, это не критичный момент. Переход на новую строку здесь является скорее правилом приличия.
Потому что, если мы запустим нашу программу без вывода \n, мы получим следующее:
$ > g++ main.cpp -o main
$ > ./main
Hello world! $ >
То есть мы не перевели терминал на новую строчку, и ввод новой терминальной команды будет перемешан с текстом, который вывела наша программа. Получилось не очень аккуратно.
Завершение
В принципе, на этом можно остановиться. Как видите, даже в самой базовой программе на C++ скрывается очень много теории, хотя я даже специально умалчивал о некоторых моментах. Но не стоит бояться: после относительно тяжёлого обучения основам дальнейшее изучение плюсов становится намного легче.
Задания к уроку "Первая программа на С++"
warning
В заданиях 1-3 использовать raw string literals запрещено!
- Перепиши программу, которая выводит на экран `Hello World!' так, чтобы каждое слово выводилось с новой строки
- Сделай так, чтобы слова в программе пункта 1 выводились не каждое с новой строки, а каждое через таб
- Напиши программу, которая выводит на экран следующий текст:
If you try to mimic this build system by hand, you'll discover that
' The GNU Build System has a lot of features.
Some users may expect features you do not use.
' Implementing them portably is difficult, and exhausting.
(Think portable shell scripts/portable Makefiles, on systems you may
not have handy.)
' You will have to upgrade your setup to follow changes of the GNU
Coding Standards.
GNU Autotools provide:
' Tools to create the GNU Build System from simple instructions.
' A central place where fixes and improvements are made.
(A bug-fix for a portability issue benefits every package.)
Конечно же, с сохранением табов и переносов строк.
- Бонус! С использованием
raw string literalsвыведи тот же текст, что и в пункте 3
Марш-бросок по основам языка
Давайте разберём самую базовую базу С++, необходимую для написания минимально полезных программ на C++.
Мы не будем вдаваться в конкретные подробности каждой темы и вообще в целом будем обо всём говорить поверхностно. Но основная цель данного урока - это просто как можно быстрее преодолеть вот этот порог, до которого "непонятно как" писать код на C++.
Переменные
Как мы упоминали ранее, С++ - это сильно типизированный язык. Это значит, что для каждой функции, для каждой переменной, и т.д. мы должны явно чётко указывать тип. Переменные на С++ объявляются следующим образом:
/*тип переменной*/ /*название переменной*/;
Пример: объявление переменной типа int с именем a:
int a = 1;
страуструп б. - программирование. принципы и практика с использованием c++
В языке С++ предусмотрен довольно широкий выбор типов (см. раздел А.8). Однако можно создавать прекрасные программы, обходясь лишь пятью из них.
int number_of_steps = 39; // int - для целых чисел
double flyinq_time = 3.5; // double - для чисел с плавающей точкой
char decimal_point = '.'; // char - для СИМВ ОЛОВ
string name = "Annemarie"; // string - для строк
bool tap_on = true ; // bool - для логических переменных
Но учтите, что string записывается как std::string - это часть стандартной библиотеки, или же стандартного пространства имён. Про пространства имён поговорим в следующих занятиях.
Скорее всего, с названием переменной у вас не будет проблем, но вот основные правила именования:
- Имена переменных могут состоять только из букв, цифр и нижних подчёркиваний
- Имена переменных не могут начинаться с цифры
- В качестве имён переменных нельзя использовать ключевые слова C++ (
return,int,double, ...) Обратите внимание! Если не инициализировать переменную при создании (то есть если ей не присвоить какое-то значение), то в ней будут лежать мусорные данные, состав которых предсказать невозможно! Поэтому, при создании переменной, обязательно нужно в неё что-то "класть" (ну, кроме случаев, когда из контекста понятно, что не будет доступа к инициализированной памяти):\
int a = 1; // правильно
int b; // тоже правильно; сразу же считываем значение b с консоли
std::cin >> b;
int c; // ОШИБКА!
std::cout << c;
Основные операторы
Арифметика
+- сложение-- вычитание*- умноженгие/- деление%- взятие остатка от деления
Пример :
int a = 5;
int b = a + 2; // b = 7
b = b - 3; // b = 4
b = b * 10; // b = 40
b = b / 2; // b = 20
b = b % 7; // b = 1 -> 21 - 20 = 1. Стандартный трюк проверки числа на делимость.
Бинарные операторы
^- XOR (исключающее или)|- OR (бинарное или)&- AND (бинарное и)~- бинарное отрицание<<- бинарный сдвиг влево>>- бинарный сдвиг вправо
Пример:
int a = 5; // 101
a = a & 4; // 100
a = a | 3; // 111
a = a << 3; // 111000
a = a >> 2; // 1110
int b = ~a; // b = 11111111111111111111111111110001 (-15)
Почему ~a получается таким большим, мы узнаем позже
Логические операторы
||- логическое или&&- логическое и!- логическое отрицание
Операторы сравнения
<- меньше>- больше<=- меньше/равно>=- больше/равно==- сравнение!=- не равняется
Логические операторы и операторы сравнения подробнее будут рассмотрены далее.
На первых порах вам не понадобяться все эти операторы. Просто бегло посмотрите, что тут есть, и выберите нужное.
Условные выражения
if (/*какое-то условие*/)
{
// что-то делаем
}
else if (/*какое-то ещё условие*/)
{
// то-то это делаем
}
else
{
// в крайнем случае делаем вот это
}
Внутри круглых скобочек if и else if нужно использовать какие-то логические выражения, которые составляются при помощи логических операторов и операторов сравнения, например:
if (1 < 2) // ...
if (first_value == second_value) // ...
if (1 > 0 && 5 < 6) // ...
if (a != b) // ...
Циклы
while
while (/*какое-то условие*/)
{
// что-то делаем
}
Цикл while - пока условие будет выполняться, выполняем какой-то набор команд.
Набор операций, записанный здесь в фигурных скобках, называется телом цикла.
Схематически while можно описать так:
- Проверь условие
- Если условие выполняется, выполни тело цикла. Если нет, выход из цикла
- Перейди к шагу 1.
do while
do
{
// что-то делаем
}
while (/* какое-то условие */)
Если нам нужно, чтобы тело цикла выполнилось как минимум один раз, мы можем использовать do-while.
Схематически do while можно описать так:
- Выполни тело цикла
- Проверь условие
- Если условие выполняется, перейди к первому шагу
for
Здесь уже поинтереснее. С помощью for мы можем создавать более сложные и выразительные циклы. Но стоит понимать, что любой цикл for можно заменить на цикл while с небольшим изменением кода.
Цикл for записывается следующим образом:
for (/* выражение 1*/; /* выражение 2 */; /*выражение 3 */)
{
}
- Выражение 1 - это операция, которую надо выполнить один раз перед запуском цикла
- Выражение 2 - это условие, при выполнении которого цикл будет завершён
- Выражение 3 - это операция, которая будет выполнена после каждого тела цикла
Пример:
for (int i = 0; i < 10; i = i + 1)
{
std::cout << i << std::endl;
}
В этом коде мы выводим на экран все числа от 0 до 9 включительно.
- Перед выполнением цикла мы выполняем операцию
int i = 0, то есть создаём переменнуюiи помещаем в неё 0 - Далее мы в цикле выводим на экран переменную
i, и потом выполняем операциюi = i + 1, то есть увеличиваемiна 1 - После этого проверям условие
i < 10, то есть, если i становится равным 10, мы выходим из цикла
задание
Переписать этот цикл, используя while
Функции
Для того, чтобы переиспользовать единожды записанный код, в С++ существуют функции (так же, как и в любом другом адекватном ЯП).
База
Синтаксис написания функций примерно следующий:
/*возвращаемый тип*/ /*название функции*/ (/*аргументы*/)
{
// тело функции - что-то делаем
}
Аргументы записываются следующим образом:
(/*тип аргумента 1*/ /*имя аргумента 1*/, /*тип аргумента 2*/ /*.....*/)
Чтобы вернуть какое-то значение из функции, мы используем ключевое слово return:
return "nya-nya-nya :3";
Пример самой базовой функции:
int mystery_function(int a, int b)
{
return a + b;
}
задание
Что делает эта функция?
Что происходит в этом коде?
- Мы объявили функцию, которая называется
mystery_function - Она возвращает значение типа
int(целое число) - Функция принимает два аргумента типа
int(a и b) - В теле функции мы возвращаем из функции значение, равное сумме переменных a и b
В коде вызвать функцию можно следующим образом:
std::cout << mystery_function(1, 2) << std::endl;
int large_number = mystery_function(101, 107);
Процедуры
Чтобы объявить процедуру (функцию, которая не возвращает никакого значения), используется ключевое слово void:
void procedure()
{
std::cout << "I am procedure!\n";
}
Так же, как видите, можно объявлять функции, которые вообще не принимают аргументов
Значения аргументов по умолчанию
int whats_my_age(int born_year = 2000)
{
std::cout << "You were born " << 2024 - born_year << " years ago\n";
}учтите, что string записывается как std::string - это часть стандартной библиотеки, или же стандартного пространства имён. Про пространства имён поговорим в следующих занятиях.
Скорее всего, с названием переменной у вас не будет проблем, но вот основные правила именования:
```cpp
std::cout << whats_my_age(1900) << std::endl; // выведется 124
std::cout << whats_my_age() << std::endl; // вывдедется 24
Ввод переменной из терминала
int a;
std::cin >> a;
Заключение
В принципе, на этом самые базовые инструменты для программирования на C++ закончились. Мы умеем создавать и инициализировать переменные, проводить над ними какие-то операции, умеем составлять условные выражения и циклы, а также можем выносить код в функции.
Также мы познакомились с основами работы с терминалом (ввод/вывод текста).
На этой основе уже можно, с небольшими оговорками, спокойно решить ЕГЭ по информатике, решать самые базовые олимпиадные задачки по программированию, и даже делать примитивные функциональные приложения.
Задания к уроку "Марш-бросок по основам языка"
- Написать программу, которая получает на вход возраст человека, и выводит, можно ли ему уже в РФ водить автомобиль
- Дополнить первую программу и сделать так, чтобы она также определяла, можно ли человеку водить мопед.
- Дополнить вторую программу с учётом того, что люди не могут быть старше 200 лет и не могут быть младше 0 лет. При вводе некорректного возраста нужно вывести ошибку.
- Бонус! Реши самую простую задачу задачу с четвёртого соревнования по спортивному программированию на сайте
Codeforces. Подсказка: для решения этой задачи можно обойтись только двумя переменными и однимif/else. - Написать программу, которая выводит первые 10 нечётных чисел через пробел на экран при помощи цикла
for. Сделать отдельно ту же программу, но с использованием циклаwhile. - Напиши программу, которая выводит на экран ёлочку:
*
***
*****
Конечно же, это надо сделать, не просто выводя заготовленную строчку :)
Вывод ёлочки вынести в отдельную функцию.
- Бонус! Сделать так, чтобы функция вывода ёлочки принимала один аргумент - нужную высоту ёлочки, и на основе этого аргумента выводила ёлочку заданной длины. Будем считать, что максимальная длина ёлочки - 15.
- Бонус! Решить первые 2 задачи с сайта https://projecteuler.net/about (можно легко нагуглить версию сайта на русском языке). Если хочешь самостоятельно продвинуться чуть дальше по материалу - можешь решить первые 5 задач.
Вообще, projecteuler - это легендарный сайт с задачками по программированию с уклоном в математику. Многие используют этот сайт для подготовки к реальным собеседованиям.
- Ультрабонус! Напиши программу, которая принимает на вход из терминала десятичное число, и выводит на экран то же число, но в шестнадцатеричной системе счисления. Для написания программы используй шаблон (обязательно):
#include <iostream>
std::string dec_to_hex(int a)
{
// ...
}
int main()
{
int a; std::cin >> a;
std::cout << dec_to_hex(a) << std::endl;
}
Фундаментальные типы данных
C++ - это сильно типизированный язык. Это означает, что у каждой переменной, у каждой функции, ..., должен быть явно указан тип.
Из-за ошибок при работе с типами данных в C и в C++ в истории человечества происходило множество страшных событий: от багов в играх до взрывающихся ракет и падающих самолётов (буквально - всё это разберём в дальнейших уроках).
Поэтому очень важно понимать, какие типы есть в С++ и как с ними работать.
Что такое тип?
Справедливый вопрос, который зачастую не обговаривается (а зря).
Обсудим это на примере переменной.
Тип - это свойство переменной, которое определяет:
- Операции, которые можно совершать над переменной (например, основные арифметические операции для целых чисел)
- Набор значений, которые может принимать переменная данного типа. Например, обычно переменная типа
intможет принимать значения от-2 147 483 647до2 147 483 647. Или, например, булева переменная (bool) может принимать значение толькоtrueилиfalse(1 или 0).
Пример того, как мы указываем тип в C++:
- При создании функций
int sum(int a, int b)
{
return a + b;
}
Здесь мы чётко указали, что функция с именем sum принимает на вход два целых числа и как результат выполнения тоже возвращает целое число
- При объявлении переменных
std::string name;
Здесь мы чётко указали, что переменная с именем name имеет тип std::string (то есть, это строка).
Переменные в памяти компьютера
Вообще, память компьютера упрощённо можно представить как бесконечную ленту из 0 и 1:
01010101000100100011110100101010010101010...
(конечно, на самом деле это не так, но в рамках курса такое объяснение вполне допустимо).
Какая-то часть этой "ленты" используется запущеными приложениями, какая-то нет.
Итак, предположим, что у нас в памяти компьютера по какому-то адресу лежит переменная.Это будет выглядеть примерно так:
...[10011101]...
То есть, у нас выделен определённый фрагмент, в который потом записали обозначенные данные.
И без типа данных вот эта последовательность нулей и единиц (бит) не имеет никакого смысла. Может быть, тут зашифрован символ в какой-то кодировке. Может, здесь зашифровано целое число. А может дробное. А может это вообще какой-то специальный крутой шифр, в котором закодирован пароль запуска ядерных боеголовок - мы не знаем. В такой ситуации, эти данные для нас только мусор.
Тип данных наделяет эту последовательность бит смыслом, и определяет то, как с этими данными можно работать. Это важно и для пользователя, который будет работать с переменной, и для компьютера, который будет выполнять над этими данными какие-то машинные операции (переместить в регистр/сложить с другим регистром/скопировать значение в другую область памяти/...).
Какие в С++ бывают типы?
страуструп б. - программирование. принципы и практика с использованием c++
В языке С++ предусмотрен довольно широкий выбор типов (см. раздел А.8). Однако можно создавать прекрасные программы, обходясь лишь пятью из них.
int number_of_steps = 39; // int - для целых чисел
double flyinq_time = 3.5; // double - для чисел с плавающей точкой
char decimal_point = '.'; // char - для СИМВ ОЛОВ
string name = "Annemarie"; // string - для строк
bool tap_on = true ; // bool - для логических переменных
Но всё же, рассмотрим представленные в C++ типы чуть подробнее.
Общее деление типов
Согласно документации, типы в C++ делятся на:
- Фундаментальные - совсем простые типы, без которых никуда не деться (
int,char,double, ...) - Составные - типы, которые, по сути, строятся на основе фундаментальных
Фундаментальные типы
Фундаментальные типы - это самые простые типы языка C++, которые служат "кирпичиками" для построения более сложных, составных типов.
Целые числа (int)
Целые числа в С++ задаются ключевым словом int. Пример:
int a = 1; // a - целое число
Вычисление границ инта
Обычно, переменная int занимает 4 байта.
В памяти целое число хранится просто в виде его представления в двоичной системе счисления.
Например, число 5 в памяти будет хранится как 101.
Из этого следует, что мы можем посчитать, какое максимальное число можно уместить в переменной типа int:
- 4 байта - это \(4 \times 8 \) = 32 бит
- Целое число может быть и отрицательным - поэтому 1 бит уходит на хранение знака числа (Если первый бит - 1, то число отрицательное, 0 - положительное). Итого на хранение самого числа остаётся 31 бит.
- 31 бит соответствует числу в двоичной системе счисления, которое может состоять максимум из 31-го символа.
- Максимальное десятичное число, которое в двоичной системе счисления будет занимать не больше 31-го символа можно вычислить как: \[ x = 2^{31} - 1 = \text{2 147 483 648} - 1 = \text{2 147 483 647} \]
Получается, что целые числа (с учётом знаковости) могут принимать значения от -2 147 483 647 до 2 147 483 647.
Спецификаторы типа
Для типа int можно задавать спецификаторы типа - это специальные ключевые слова, которые уточняют тип переменной int. Давайте разберёмся, какие они бывают.
- Уточняющие знаковость целового числа (может ли число быть положительным или нет) -
signedиunsigned.intпо умолчаниюsigned. - Уточняющие размер числа -
short,long,long long. Так мы можем определить, с насколько большим целым числом мы хотим работать (и, соответственно, сколько памяти нужно выделять для хранения этого числа).
Если число будет беззнаковое (unsigned), то в нём для хранения самого числа выделяется уже не 31, а 32 бита (так как отдельный бит для хранения знака уже не нужен). Получается, числа unsigned int могут лежать в пределах от 0 до \( 2^{32} - 1 = \text{4 294 967 296} - 1 = \text{4 294 967 296}\).
По поводу размеров int обычно работает следующая шкала:
short int- 2 байтаint- 4 байтаlong int- 8 байтlong long int- 16 байт
Для этих типов диапазоны значений высчитываются аналогично. При желании, их можно самому легко посчитать в калькуляторе, или банально нагуглить.
...с помощью спецификаторов можно задавать переменные типа int самыми разными способами:
int a;
short int b;
short c;
long d;
long long e;
signed int f;
unsigned int g;
unsigned long long int h;
// и т.д.
То есть, можно как угодно сочетать спецификаторы, определяющие размер и знаковость числа. Так же можно опускать при определении типа слово int, если уже используется, например, long long или signed.
Реальный размер инта
Очень тонкий момент заключается в размере int. Да, обычно, размеры int такие, как я написал. Но это только обычно, а не всегда. На самом деле, размер int может различаться на разных платформах! Это определяется разрядностью и архитектурой процессора, и другими особенностями. Если взглянуть в официальную документацию C++, то размеры int там определены следующим образом:
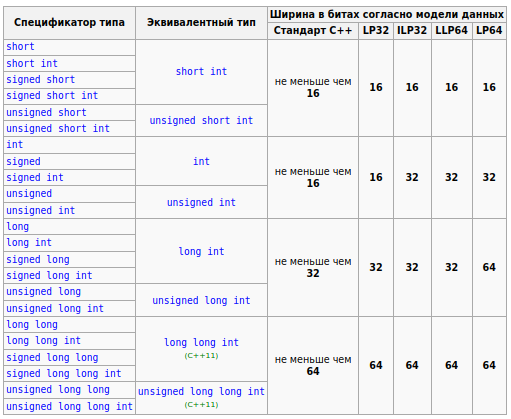
Обратите внимание на словосочетание: "не меньше чем". Стандарт С++ не гарантирует точный размер переменной типа int! По таким ограничениям, short int может быть такого же размера, как int.
Почему же существует такая путаница и неразбериха? Потому что C++ позволяет очень "близко" (на низком уровне) работать с целевой машиной, на которой работает программа. Поэтому такой базовый тип, как int, и зависит от аппаратных возможностей конкретного конкретного компьютера, на котором будет собрана и запущена программа.
Но всё не так плохо! Если мы захотим, мы можем создать переменную int, которая будет ровно того размера, который нам нужен.
Чтобы чётко указать компилятору, что мы хотим переменную int размером в столько-то байт, существуют специальные типы:
int32_t a; // Переменная signed int размером 32 бита (4 байта)
int8_t b; // Переменная signed int размером 8 бит (1 байт)
uint16_t c; // Переменная unsigned int размером 16 бит (2 байта)
На самом деле, это не отдельные типы, а просто заранее определённые typedef-псевдонимы. Они на этапе компиляции "подгоняются" под целевую машину, и, например, вместо int16_t на этапе компиляции может подставиться short int. Что такое typedef, мы разберём подробнее позже.
Числа с плавающей точкой
...или же дробные числа, или же вещественный числа, или же числа со знаками после запятой.
Для хранения вещественных чисел в C++ используется 3 типа данных:
floatdoublelong double
С целыми числами все понятно, как они хранятся в памяти: это просто последовательность бит, которая в двоичной системе соответствует целому числу. Последовательность бит 10 означает \( 2_{10}\), 11 - \(3_{10}\), и так далее.
Хранить же дробное число, так же как и выполнять с ним какие-то операции, на уровне бинарной арифметики, достаточно сложно и неудобно. Отсюда зачастую можно встретиться вот с таким интересным поведением программ (и не только на языке C++):
float f = 0.6;
std::cout << (f/2 == 0.3); // 0 (false)
На эту тему можно посмотреть отдельный ролик.
Здесь же скажем коротко: существуют специальные стандарты, которые определяют, как в компьютере будет храниться дробное число, и которые определяют допустимый размер дробного числа.
Выдержка из документации касательно стандартов представления дробных чисел:
cppreference.com
- float - тип с плавающей запятой одинарной точности. Соответствует формату IEEE-754 binary32, если поддерживается.
- double - тип с плавающей запятой двойной точности. Соответствует формату IEEE-754 binary64, если поддерживается.
- long double - тип с плавающей запятой повышенной точности. Соответствует формату IEEE-754 binary128, если поддерживается, в противном случае соответствует IEEE-754 binary64-расширенному формату, если поддерживается, иначе соответствует некоторому расширенному формату с плавающей запятой, отличному от IEEE-754, если его точность лучше, чем binary64, и диапазон не менее хорош как binary64, иначе соответствует формату IEEE-754 binary64.
Размеры для этих типов распределяются так:
float: представляет вещественное число одинарной точности с плавающей точкой в диапазоне+/- 3.4E-38 до 3.4E+38. В памяти занимает 4 байта (32 бита)double: представляет вещественное число двойной точности с плавающей точкой в диапазоне+/- 1.7E-308 до 1.7E+308. В памяти занимает 8 байт (64 бита)long double: представляет вещественное число двойной точности с плавающей точкой не менее 8 байт (64 бит). В зависимости от размера занимаемой памяти может отличаться диапазон допустимых значений
Символьные типы
char
Для представления символов в C++ используется тип char.
Символы в языке C++ обозначаются через одинарные кавычки:
char a = 'D';
Обратите внимание, что в C++ существует чёткое разделение между символами и строками (в отличие от того же питона). Поэтому символы обозначаются здесь одинарными кавычками, а строки - двойными.
Для хранения текста в памяти компьютера вообще (в отрыве от С++) существует огромное число разных кодировок:
- ASCII
- KOI8R
- Windows1251
- UTF8 / UTF16 / UTF32
- ...
В C++ для типа char используется очень простая кодировка ASCII. В этой кодировке самым основным символам предоставляется численный код от 1 до 127:

Благодаря этой кодировке, char занимает в памяти только 1 байт. Но с помощью него нельзя хранить специальные символы (эмодзи, математические символы), или символы из алфавитов разных языков (например, иероглифы).
В кодировке ASCII каждому симолу просто присваевается какое-то число от 0 до 127. Таким образом, символ "!" может быть закодирован как число 33, символ "N" как число 78, и так далее.
Ну и, соответственно, символ в кодировке ASCII в памяти будет хранится как то же самое целое число. Или же, другими словами, последовательность бит, в виде которой хранится в памяти переменная char, соответствует коду сивола в таблице ASCII в двоичной системе счисления.
По этой причине, значения типа char могут использоваться вместе с целыми числами:
int D_ascii_code = 'D'; // Будет хранить 68 - код 'D' в таблице ASCII
char a = 33; // В переменную a запишется символ с ASCII-кодом 33. То же самое, что a = '!';
int b = a + 15; // здесь вместо a подставится ASCII-код лежащего там символа. b = 33 + 15 = 48
char c = 'A' + 1; // После символа 'A' в таблице ASCII лежит символ 'B'. c = 'A' + 1 = 65 + 1 = 66 = 'B'
Формально, char может принимать отрицательное значение (1 бит в его двоичном представлении выделяется на знак). Можно объявить переменную с типом unsigned char, тогда она будет принимать значения от 0 до 255.
Но правило в этом плане следующее: всегда используйте только char; unsigned char используйте только в тех редких случаях, когда вы очень чётко представляете, зачем вам это нужно.
У использования char для хранения символов есть некоторые минусы:
- Реализация
char, так же как иint, различается на разных платформах. - С помощью
charможно хранить только очень небольшой перечень доступных символов
Для решения второй проблемы существует отдельный тип - wchar_t, или же "широкий char".
wchar_t
С помощью этого типа мы можем хранить и выводить на экран хоть эмодзи, хоть иероглифы.
"Под капотом" в wchar_t хранятся символы в кодировке Unicode.
Пару слов про Unicode. Юникод работает по тому же принципу, что и ASCII - каждому символу присваевается какой-то код, и в конечном итоге число в памяти компьютера хранится как этот код.
В отличие от ASCII, в юникоде поддерживается намного больше символов (десятки тычяч против 128).
Также, у юникода есть несколько разновидностей:
UTF-8. В этой кодировке каждому символу в памяти выделяется ЛИБО 8, либо 16, либо 32 бита. То есть, размер символа в этой кодировке - непостоянный.UTF-16. В этой кодировке каждому символу в памяти выделяется либо 16, либо 32 битаUTF-32. В этой кодировке каждый символ занимает в памяти чётко 32 бита.
Про кодировки UTF-8 и UTF-16 говорят, что символы в этих кодировках
соответствуют какому-то количеству кодовых единиц:
- Символы в
UTF-16могут занимать одну (16 бит) или две (32 бита) кодовые единицы. - Символы в
UTF-8могут занимать одну (8 бит), две (16 бит) или четыре (32 бита) кодовые единицы.
question
Почему 32 бита в UTF-16 соответствуют 4 кодовым единицам, а не 3?
...зачем же нам нужен непостоянный размер символов в кодировке? Это помогает сократить использование памяти: для символов, которые спокойно умещаются в 1 байт (их номер не превосходит 255), не придётся выделять в памяти лишние 3 байта.
Но, одновременно с этим, увеличивается сложность обработки текста с непостоянным количеством бит на каждый символ.
...из-за того, что wchar использует unicode, стоит понимать, что он принципиально отличается от char, и просто так заменить один тип на другой не получится, потому что алгоритм работы с разными кодировками сильно различается.
Например, вот так будет выглядеть вывод одного символа с использованием wchar_t:
#include <iostream>
int main()
{
wchar_t symbol = L'🍌';
std::wcout << symbol << std::endl;
}
Здесь можем заметить сразу несколько вещей:
- Для
wchar_tнужно использовать специальный потокwcout - Для обозначения шикроких символов нужно писать
L''- подробнее об этом расписано в статье про литералы
Если попытаться в коде выше заменить wcout на cout, компилятор откажется компилировать этот код.
Но у wchar_t есть один минус: "под капотом" у него не всегда используется одна и та же вариация юникода.
Например, на Linux-машинах это обычно UTF-32 - wchar_t занимает 32 бита и поддерживает все доступные в юникоде символы.
На Windows-машинах же зачастую используют 16 бит для представления символов, и поэтому в wchar_t помещаются не все юникод-символы.
Эту проблему видно даже на нашем примере: если в системе, на которой запускается этот код,
для whcar_t используется 16 бит, код эмодзи просто в них не поместится, и на экран выведется мусор.
char8_t, char16_t и char32_t
Для тех случаев, когда мы чётко хотим определить используемую кодировку, используются типы char8_t, char16_t и char32_t.
- В
char8_tхранятся символыUTF-8, которые помещаются в 8 бит - В
char16_tхранятся символыUTF-16, которые помещаются в 16 бит - В
char32_tхранятся символыUTF-32.char32_tв памяти занимает 32 бита.
В коде их использование может выглядеть примерно так:
char8_t C1 = u8'a';
// char8_t C2 = u8'¢'; // ошибка: ¢ соответствует двум кодовым единицам UTF-8
// char8_t C3 = u8'猫'; // ошибка: 猫 соответствует трём кодовым единицам UTF-8
// char8_t C4 = u8'🍌'; // ошибка: 🍌 соответствует четырём кодовым единицам UTF-8
print("\n" "UTF-16 character literals:");
char16_t uc1 = u'a';
char16_t uc2 = u'¢';
char16_t uc3 = u'猫';
// char16_t uc4 = u'🍌'; // ошибка: 🍌 соответствует двум кодовым единицам UTF-16
print("\n" "UTF-32 character literals:");
char32_t Uc1 = U'a';
char32_t Uc2 = U'¢';
char32_t Uc3 = U'猫';
char32_t Uc4 = U'🍌';
(пример с cppreference).
Вообще, нам в курсе эти типы вряд ли потребуются, но полезно знать, что это такое и зачем оно нужно.
Логический тип
Для представления булевых/логических значений, в C++ используется тип bool.
Переменные типа bool могут принимать только два значения: true или false (1 или 0).
Пример использования:
bool a = true; // 1
bool b = false; // 0
bool c = a | b; // 1 | 0 = 1
В памяти bool занимает один байт. Возможно, у вас возникнет вопрос, почему не один бит, ведь bool по сути хранит только один или ноль.
Ответ на этот вопрос достаточно сложный, но если попытаться ответить на него коротко, то компьютер не может так дробить память, чтобы выдавать нам ровно 1 бит под хранение переменной. 1 байт - это минимальный размер "долек", на которые компьютер может "дробить" память.
Составные типы
Это типы, которые являются "надстройками" над фундаментальными типами. К таким типам можно отнести:
- Указатели и ссылки
- Массивы
- Функции и функторы
- Перечисления
- Классы
Что это всё такое, сейчас разбирать не будем, потому что, по сути, большая часть нашего курса как раз и посвящена обсуждению того, что это за такие типы :)
Бонус: std::string
Чтобы полностью осознать, что из себя представляет на самом деле std::string, нам потребуется ещё несколько уроков, но пока, чтобы создавать минимально функциональные приложения, можно просто запомнить, как его использовать.
std::string используется для хранения строк в C++. Стоит понимать, что это не фундаментальный тип - ведь std::string является не чем-то отдельным, а просто надстройкой над char.
Пример использования std::string:
int main()
{
std::string name = "Maxim";
std::cout << "Hi, " + name << " !" << std::endl;
}
Источники
- Статья про типы из оф. документации
- Программирование. Принципы и практика использования C++ - Бьерн Страуструп
- Статья про фундаментальные типы из оф. документации
- Видео про дробные числа (Why Is This Happening?! Floating Point Approximation)
- IEEE 754-2008 - вики
Задание к уроку "Фундаментальные типы данных"
Условие
Требуется написать программу, которая будет переводить число из двоичной системы счисления в десятичную.
Пример вызова готовой программы
% ./bin2dec
Введите число: 101
Десятичное представление: 5
%
Входные данные
На вход программа получает число, записанное в двоичной системе счисления без пробелов.
Число строго положительное и не превосходит \(\text{2 000 000 000}_{10} \).
Выходные данные
Введённое число в десятичной системе счисления
Ограничения на выполнение
Необходимо разработать функцию to_bin, возвращающую тип std::string.
Эту функцию потом нужно будет вызвать в main для вывода ответа.
Например, так:
std::cout << "Десятичное представление: " << to_bin(number) << std::endl;
Пользоваться сторонними библиотеками, std::bitset и прочими хитростями, конечно же, запрещено.
Справка
Необходимые операции над строками, нужные для выполнения:
- Добавление символа (или символов) в конец строки:
std::string name = "Ivan";
name += " Ivanov";
- Обращение к конкретному символу строки (массива):
std::string name = "Vladimir";
std::cout << name[0] << name[2] << name[5] << std::endl; // Vam
- Получение размера строки:
std::string name = "Maxim";
std::cout << name.length() << std::endl; // 5
Непосредственно алгоритм перевода числа из двочной системы счисления в десятичную, если будут затруднения, можно легко нагуглить.
При стандартном подходе в конце работы функции to_bin необходимо будет перевернуть строку. Предполагается, что этот алгоритм ты сможешь написать сам - но, в любом случае, при затруднениях идею можно тоже очень легко нагуглить.
Но если ты и будешь какие-то алгоритмы подсматривать в интернете - очень важно, чтобы ты не просто копировал код: ты должен посмотреть и запомнить саму идею, основной принцип работы алгоритма, и потом из памяти перенести его в свой код.
Дополнительные задания
Если ты справишься с основным заданием, и захочешь что-то сделать сверх него, предлагаю следующие задачи:
- Добавить проверку корректности введённого бинарного числа: по символам и по размеру.
- Добавить поддержку ввода бинарного числа с пробелами (см. функцию
getline). - Добавь поддержку отрицательных чисел. При таком подходе первый бит числа будет отвечать за знак (т.е. формат ввода не меняется). В ответе выводе число с
-или+в начале. Так же проверяй входные числа на минимальный размер (2 символа).
Операции и операторы
Вспомним, что мы говорили о типах данных. Тип данных в первую очередь определяет то, какие операции мы можем совершать над данными.
А операции над данными - это одна из самых базовых (в плане простых и в плане необходимых) вещей в программировании в целом.
Давайте посмотрим на то, какие операции в принципе есть в С++.
Операции и операторы
Операция - это конкретное действие, которые производится над данными. Сложение, умножение, и так далее.
Операторы - это же специальные символы, с помощью которых мы создаём операции.
Например, оператор + задаёт для целых чисел операцию сложения.
Обратите внимание: каждая операция в C++ определена для конкретных типов, а не для всех сразу.
Операторы в С++ могут для разных типов обозначать разные операции - например, + обозначает сложение для целых чисел и конкатенацию для строк (об этом далее).
У каждой операции есть возвращаемый тип данных
Стоит помнить, что каждая операция в C++ возвращает какое-то значение, привязанное к конкретному типу данных.
Самое очевидное - это арифметические операции, по типу + и -. Но стоит помнить, что операции логического сравнения, присваивания, и любые другие тоже возвращают значение какого-то определённого типа данных.
Присваивание
Самая базовая операция.
int a = 1;
a = 8;
Выполняется при помощи оператора присваивания =.
Оператор = возвращает значение, которое было с помощью него записано в переменную, поэтому возможна следующая запись:
int a;
int b;
a = b = 4;
Здесь сначала выполнится b = 4, вернёт 4, и потом выполнится a = 4.
Базовая арифметика
Здесь всё просто. С целыми и дробными числами мы можем выполнять базовые арифметические операции:
int a = 9 + 2;
int b = 9 - 2;
int c = 9 / 2;
int d = 9 * 2;
Это сложение, вычитание, деление и умножение.
Порой нам нужно к уже имеющейся переменной добавить число, или поделить переменную на число, или сделать с ней ещё какую-то базовую арифметическую операцию.
Писать это через операции сложения, деления, и т.д. напрямую достаточно неудобно:
int a = a + 1;
Поэтому, для таких случаев в C++ есть специальные операторы:
a += 9; // a = a + 9;
b -= 9; // a = b - 9;
c /= 9; // c = c / 9;
d *= 9; // d = d * 9;
Остаток от деления
Очень часто в программировании нам нужно использовать такую операцию, как остаток от деления. Записывается она так:
int a = 5 % 2;
Что такое остаток от деления, я надеюсь, вы знаете из школьного курса - грубо говоря, это тот остаток, который у нас остаётся от числа, когда мы пытаемся его нацело поделить в столбик.
Остаток от деления зачастую используется, например, для проверки того, что одно число делится на другое - в случае, если число a делится на число b, остаток от деления a на b (a % b) должен равняться 0, и какому-то числу от 0 До b в противном случае.
Для остатка от деления также есть оператор со знаком равенства:
a %= 5;
Префиксное увеличение
Для того, чтобы добавить к числу 1, можно использовать оператор префиксного увеличения. Выглядит это примерно так:
++a;
Префиксное - потому что оператор ++ записывается перед увеличиваемым значением.
Постфиксное увеличение
Также в C++ доступно и постфиксное увеличение переменной:
a++;
В этом случае к переменной a тоже будет добавлена единица
Различие префиксного и постфиксного увеличения
Как конечный итог выполнения, и a++ и ++a прибавляют к a единицу. Но всё таки у этих операторов есть чёткое различие, и оно заключается в возвращаемом значении.
Если выполнить следующий код:
int a = 1;
std::cout << a++ << std::endl;
...на экран выведется 1. То есть, при обращении к a++, мы получаем число до прибавления 1.
Если же поменять a++ на ++a, на экран выведется 2.
Префиксное и постфиксное уменьшение
Здесь всё абсолютно аналогично увеличению, но вместо прибавления единицы, происходит вычитание единицы, а операнд ++ заменяется на операнд --.
Операции сравнения
Здесь, в принципе, тоже нет ничего нового.
Основные операции сравнения в C++ записываются как:
>, >=, <, <=.
Единственные особенности касаются операций проверки равенства двух чисел (==) и неравенства (!=).
Все эти операторы возвращают значение типа bool.
С оператором сравнения чисел == существует классическая ошибка, которую нам нужно обязательно рассмотреть:
int b;
std::cin >> b;
if (b = 5)
{
std::cout << "You guessed the number!\n";
}
На первый взгляд, может быть, ошибку и сложно заметить, но она заключается в том, что в if мы вместо оператора сравнения == использовали оператор присваивания =.
Причём этот код будет успешно скомпилирован и запущен, но условие if будет выполняться для любых введённых значений b. Почему?
Как уже говорилось ранее, каждая операция возвращает какое-то значение. Операция присваивания не исключение - она будет возвращать присвоенное значение.
В данном случае, операция b = 5 вернёт 5, которое потом преобразуется в bool по цепочке преобразований (см. урок о приведении типов). Из-за этого тело условного оператора будет выполняться всегда, и порой такую ошибку бывает очень сложно заметить.
Логические операции
Для составления логических условий так же используются логические операции. Все они возвращают значение типа bool.
Логические операторы:
||- или. Принимает на вход два аргумента типаbool. Возвращаетtrue, если хотя бы один из аргументовtrue.&&- и. Принимает на вход для аргумента типаbool. Возвращаетtrueтолько если оба аргумента тожеtrue.!- не. Принимает на вход один аргумент и возвращает его противоположное значение.
Простой пример:
int age = 17;
if (age > 16 && age < 18)
{
std::cout << "Вам можно только ездить на мопеде.\n";
}
Что здесь происходит:
- Сначала вычисляется
age > 16- операция сравнения возвращает булевое значение - Аналогично справа
- Потом оператор
&&подхватывает эти два значения и как-то обрабатывает
Другой пример - проверка того, что число делится на 3 или на 5:
int number = 18;
if (!(number % 3) || !(number % 5))
{
std::cout << "Делится на 3 или на 5.\n";
}
Что происходит здесь?
- Компилятор видит выражение с или, и начинает разбирать левую его часть. Для начала вычисляется выражение в скобках. Как "промежуточный" результат получаем:
if (!0 || !(number %5))
- Оператор
!умеет работать только с булевыми значениями, поэтому компилятор выполняет цепочку преобразований для целого значения 0, и мы получаем:
if (!false || !(number % 5))
- Применяем отрицание:
if (true || !(number % 5))
- И здесь наступает очень важный момент. Оператор
||видит, что справа от него уже стоит значениеtrue. Зачем ему тогда проверять значение справа, если результат или уже гарантированно будетtrue? На этом шаге оператор сразу возвращаетtrue, без вычисления!(number % 5)
И в этой "оптимизированной" проверке заключается особенность логических операций сравнения. Нагляднее это можно продемонстрировать, используя отдельную функцию:
#include <iostream>
int f()
{
std::cout << "f()\n";
return 5;
}
int main()
{
if (!(false && f()))
{
std::cout << "Obviously false statement is false.\n";
}
}
Если запустить этот код, в терминал не выведется строка f(), что значит, что функция f() даже не вызвалась, так как левый аргумент оператора && уже был false.
Бинарные операции
x & y // бинарное И
x | y // бинарное ИЛИ
x ^ y // бинарное НЕ-ИЛИ (XOR)
~x // бинарное НЕ
В случае этих операторов, над входящими аргументами производятся именно бинарные операции, то есть честно будут выполнятся все перемещения, сложения (и т.п.) битов входящих чисел.
Про то, что такое в теории бинарные операции, рассказано в отдельной статье.
Здесь очень важно понимать различие x & y и x | y от x && y и x || y.
Как мы уже обсуждали, логические операторы просто проверяют два булевых значения и возвращают такое же булевое значение, выполняя по возможности простые оптимизации.
Бинарные же операторы принимают на вход два числа (или 1 в случае отрицания) и возвращают как результат своих действий такое же число - результат применения ко входным данным конкретной бинарной операции. В этом случае вне зависимости от значений аргументов при любых обстоятельствах будут происходится просто вычисления над битами.
Унарные операции
Частично мы уже затронули унарные операции - это операции, которые принимают на вход только один аргумент. К ним можно также добавить:
-- возвращаетчисло * (-1)+- используется для того, чтобы намеренно указать на положительность какого-то числа. Используется не так часто, так что пока можно сильно в смысл унарного+не вникать.
Операции над строками
Над строками тоже можно делать базовые операции. Бегло рассмотрим два примера.
Конкатенация - объединение двух строк:
std::cout << "Hello " + "world\n" << std::endl;
В данном случае оператор + вернёт строку Hello world\n.
Обратите внимание, что в этом случае мы не говорим об операции сложения - мы говорим именно об операции конкатенации, потому что объединение двух строк и сложение двух чисел - это совершенно разные операции как на уровне идеи, так и на уровне реализации.
Добавление в конец
std::string greetings = "Hello";
greetings += '!';
С помощью оператора += можно добавить в конец строки символ или строку.
Ключевое слово auto
В C++, начиная с С++11, существует ключевое слово auto. Оно позволяет не прописывать тип переменной при её создании и определять его автоматически из выражения, которое используется для инициализации переменной.
Например:
auto year = 1918;
Компилятор увидит справа целое число и заменит auto на int.
По очевидным причинам, переменная, создаваемая при помощи типа auto должна сразу же быть проинициализирована - иначе компилятор не сможет понять, к какому типу она принадлежит.
Очень важно понимать, что использование auto не означает, что мы создаём какую-то переменную "без типа".
auto - это просто синтаксический сахар для более удобного определения переменных.
Реальный пример использования
std::map<std::string, std::pair<std::optional<int32_t>, std::vector<std::string >>> f()
{
// ...
}
Предположим, у нас есть вот такая функция с ужасно длинным в плане написания возвращаемым значением. В данном контексте не важно, что такое std::map, std::string и прочее (это будет рассмотрено на следующих уроках) - важно только то, что возвращаемое значение очень длинное.
И теперь представим, что нам нужно положить результат выполнения этой функции в какую-то переменную. Без auto, нам снова пришлось бы вручную прописывать весь этот ужас. А что, если нам нужно создать 5 переменных, которые хранят результат вызова этой функции?
Здесь как раз идеальная ситуация для использования auto:
auto f_result = f();
Источники
Приведение типов данных
Итак, мы знаем, что в памяти компьютера каждый тип данных хранится по-разному.
Типы данных занимают разное количество памяти и могут распознаваться компьютером совершенно по-разному.
Но всё же зачастую нам нужно преобразовывать данные из одного типа в другой.
Такое преобразование называется приведением типов, или же type casting.
Явное приведенеи типов
Мы можем напрямую попросить компилятор преобразовать значение из одного типа в другой.
C-style casting
Так как C++ является продолжением языка C, в целях совместимости этих двух языков в C++ остаётся много инструментов из C.
Одним из них является C-style casting, или же преобразование типов в стиле C.
Записывается оно следующим образом:
int a = 4;
std::cout << (double)a << std::endl;
внимание!
Использовать C-style casting - плохая практика
Но использовать такое преобразование, кроме того, что это достаточно плохо читается в коде, не рекомендуется по нескольким причинам:
- При таком преобразовании компилятор не будет проверять, насколько такое преобразование безопасно. Поэтому мы можем случайно спровоцировать потерю данных, неопределённое поведение нашей программы или даже аварийное завершение.
- Преобразование в стиле С может даже снимать константность с переменных
Статическое приведение типов - static_cast
Такое приведение уже избавлено от недостатков C-style casting. Его мы и будем использовать для явного приведеня типов.
Записывается оно при помощи static_cast:
int a = 4;
std::cout << static_cast<double>(a) << std::endl;
В угловых скобках указывается тип, к которому мы хотим преобразовать данные, а в круглых - сами преобразуемые данные.
Другие C++-преобразования
В следующих уроках мы рассмотрим подробнее и другие преобразования:
dynamic_castconst_castreinterpret_cast
На данный момент мы разобрали ещё недостаточно материала, так что пока отставим эти темы на потом.
Неявное приведение типов
Также в C++, как и в C, часто работает неявное приведение типов. В таких случаях значение одного типа данных без наших инструкций, по решению компилятора преобразуется в значение другого типа.
Нежелаемое неявное приведение типов в программе может привести к очень опасным последствиям, вплоть до взрыва космических ракет, управляемых программой на C/C++.
Поэтому нужно очень чётко понимать, когда срабатывает неявное приведение типов.
Общий случай
Вообще, все ситуации с неявным приведением можно свести к общему правилу: когда компилятор видит, что один тип данных используется в контексте другого типа данных, он будет пытаться привести второй тип данных к первому (если мы ему это, конечно же, не запретили).
Если же компилятору нужно выбрать, к какому типу нужно привести значение, он всегда будет стараться подобрать тип с наименьшей потерей информации. Конкретный пример посмотрим далее для оператора сложения +.
Операторы
Когда мы используем стандартные операторы, так же стоит понимать, что конкретные операции в C++ определены только для конкретных типов.
Например, сложение в C++ через + определено только для:
- двух целых чисел
- двух вещественных чисел
Соответственно, при вызове следующей операции:
double a = 5.2 + 4;
...оператор + без преобразований не сможет вычислить эту сумму.
Ему придётся либо 5.2 привести к инту, либо 4 привести к float. Что же он сделает?
Конечно же, компилятор видит, что если он приведёт 5.2 к инту, произойдёт потеря информации - мы потеряем дробную часть числа. А если он приведёт 4 к float, ничего не потеряется - поэтому в данному случае произойдёт именно преобразование 4 к float, после чего будет вычислен результат сложения двух вещественных чисел.
Ещё один очень наглядный и базовый пример - это деление.
Как вы думаете, что будет выведено на экран при исполнении этого кода?
std::cout << 5/2 << std::endl;
И 2.5 - это неправильный ответ! На самом деле, на экран выведется число 2. Давайте разберёмся, почему.
У нас есть оператор /, который принимает два аргумента.
В данном случае и левый, и правый операторы - это целые числа. На основе входных данных (два целых числа), оператор считает, что он также должен вернуть целое число. Поэтому, 5 делится на два с учётом того, что результат должен быть целым числом. Из-за этого дробная часть просто выкидывается, и на выходе мы получаем число 2.
Как исправить этот код? Чётко сказать компилятору, какой тип мы хотим получить. Например, задать один из аргументов как число с плавающей точкой:
std::cout << 5.0 / 2 << std::endl;
...или так:
std::cout << static_cast<float>(5)/2 << std::endl;
В данном случае оператор получает одно число с плавающей точкой и одно целое, и на основе этой информации принимает решение возвращать тоже число с плавающей точкой, чтобы избежать потери данных.
Если быть точнее, оператор / определён только для работы либо с двумя интами, либо с двумя вещественными числами. Когда мы задаём одно число как вещественное, компилятор преобразует второе число в вещественное и правильно вычисляет результат (по аналогии с только что рассмотренным примером сложения).
замечание
Если применить static_cast ко всему выражению:
std::cout << static_cast<float>(5/2) << std::endl;
...у нас всё равно выведется 2.
Потому что в данном случае оператор / всё равно примет на вход 2 целых числа
и точно также вернёт значение int, и уже это готовое целое число будет формально
преобразовано к типу float.
Вызов функций
Предположим, у нас есть абстрактная функция для сложения двух чисел с плавающей точкой:
double double_sum(double a, double b)
{
return a + b;
}
...и позже, где-то в коде, нам захотелось вызвать эту функцию для двух целых чисел:
int height_table, height_vase;
// ...
std::cout << double_sum(height_table, height_vase);
В этом случае тоже будет произведено неявное преобразование целых чисел в вещественные.
Инициализация
Когда мы инициализируем переменную через оператор =, тоже может возникнуть неявное преобразование.
Например, следующий код:
int a = 4.0;
В этом случае, при инициализации целого числа вещественное число справа неявно преобразуется в int.
Чтобы избежать неявного преобразования типов при инициализации, можно использовать универсальную инициализацию:
int a {4.0};
Такой код компилятор уже откажется компилировать и резонно укажет нам на различие типа переменной и присваеваемого значения.
Условие if
Когда мы пишем условный оператор if, в круглых скобках мы указываем условие, при котором должно быть выполнено тело if (команды в фигурных скобках).
Это условие, как нетрудно догадаться - это на самом деле какое-то значение типа bool. Если оно равняется true, то тело выполняется, если false, то нет.
И если передать в круглые скобки if какое-то не булевое значение, произойдёт неявное преобразование типа в bool:
int a; std::cin >> a;
if (a)
{
std::cout << "a is null!\n" << std::endl;
}
Здесь a - это целое число. if принимает только булевые значения, поэтому компилятор выполняет неявное преобразование из int в bool.
Вообще, преобразования каких-либо типов в bool работают очень просто: если значение не ноль - результирующий bool будет true, иначе - false.
Так и в нашем примере - если a == 0, то тело выполнется, иначе нет.
Опасное и безопасное приведение типов
Как мы видим, типы в C++ можно преобразовывать и изменять совершенно по всякому. Но стоит понимать, что приведение типов допустимо далеко не во всех ситуациях.
Приведение типов считается безопасным, если оно не может потенциально привести к потере данных.
Например, преобразование int в long int - безопасное, потому что число, хранящееся в инте, со стопроцентной гарантией поместится в long int.
В целом, это правило можно немного расширить: всякое преобразование из типа данных, который занимает меньшие объём памяти, к типу данных, который занимает больший объём памяти, является безопасным. Некоторые примеры:
charвshort int,int,long int,double, ...intвdouble,long long int, ...doubleвlong long int
Если же преобразование типов может привести к потере данных, то такое преобразование называется опасным.
Например, приведение типа int к типу char. Если в int-е хранится число, большее 255, оно просто не поместится в char, и в итоговой переменной мы получим "оборванное значение".
Легко можно это визуализировать, представив себе коробки с песком. Если насыпать в большую коробку чуть-чуть песка - ничего плохого не случится, несмотря на то, что часть коробки будет не занята - это безопасное приведение типов.
Но если мы попытаемся в маленькую коробку засыпать камаз песка - часть песка высыпется из коробки и будет утеряна - это будет небезопасное приведение типов.
Как это выглядит на уровне памяти?
Пусть у нас есть переменная int a, в которой лежит значение 300. В памяти компьютера это будет выглядеть так:
00000000000000000000000100101100
(32 знака, потому что int, обычно, занимает 4 байта).
Дальше мы хотим это значение привести к типу char. Что сделает компьютер? Правильно, он просто обрежет наше число:
000000000000000000000001[00101100]
char занимает 1 байт, поэтому компьютер "обрезает" от числа последние 8 бит.
Но в итоговый char не попала одна единичка из исходного числа, потому что она просто не влезла в границы char-а!
В итоге, мы получим в char значение 44 вместо 300.
Самым наглядным примером небезопасного преобразования типов, которое привело к необратимым последствиям, является крушение ракеты Airane 5.
В этом случае в программе 64-битное вещественное число преобразовывалось к 16-битному целому числу, из-за чего ракета, стоившая сотни миллионов долларов, взорвалась при старте. Подробнее на эту тему можно почитать прекрасную статью с хабра, её я оставлю в источниках.
Мораль
Всегда следите за преобразованием типов в своей программе, используйте статическое приведение типов и не забывайте отслеживать в своей программе неявные (и явные тоже) небезопасные преобразования.
Источники
- Статическая типизация и преобразования типов - Metanit
- Космическая ошибка: $370 000 000 за Integer overflow - Хабр
- Ariane 5 rocket launch explosion - Youtube
Переполнение типа
Ещё один очень важный аспект работы с типами данных - это переполнение.
Мы уже косвенно сталкивались с ним при рассмотрении небезопасного преобразования типов, но давайте поговорим об этом подробнее.
Что это такое
Переполнение переменной - это ситуация, когда мы пытаемся сложить в переменную значение, которое в неё не помещается.
Можно себе представить аналогию с коробками и песком. Если переменная (коробка) занимает определённое количество памяти (вмещает в себя определённое количество песка), и мы пытаемся положить в неё слишком "большие" данные (засыпаем в неё слишком большое количество песка), часть данных будет потеряна (часть песка просто высыпется).
Частично переполнение уже обсуждалось в статье про приведение типов, в разделе о небезопасных преобразованиях - там мы разбирали, что происходит, когда мы пытаемся в переменную типа char сложить число 300.
Пример переполнения
Предположим, что в переменной char a уже лежит число 127. В бинарном виде это будет выглядеть как:
01111111
Тип char формально может принимать и отрицательные значения, поэтому первый бит, по аналогии с int, равен 0.
Что же будет, если мы попытаемся к переменной a добавить ещё единицу? Результат в принципе будет предсказуем. Бинарное представление переменной будет выглядеть так:
10000000
Как видим, первый бит теперь равен 1 - а это для типа char это означает, что число отрицательное. Далее, за битом знака, идут только нули. -0 автоматически переведётся в -128.
Получается, мы хотели в char положить 128, а получилось, что там теперь лежит -128.
Аналогично, если мы попытаеимся в char положить заведомо слишком большое число, например 300:
100101100 -> 1[00101100]
Квадратными скобками здесь я выделил часть числа 300, которая непосредственно будет записана в переменную char. Таким образом, мы запишем в переменную не число 300, а число \( 101100_2 = 44_{10} \).
Последствия переполнений переменных в реальном мире
Как я уже говорил, в истории человечества было множество примеров, когда неправильная работа с типами данных в С/C++ приводила к катастрофическим последствиям. Когда-то это были потерянные огромные суммы денег, когда-то это были реальные человеческие жертвы. Иногда это просто вызывало небольшой дискомфорт для пользователей программы, но всё равно критичность ошибки это сильно не меняет.
Therac-25
В 1985-1987 медицинской аппаратурлй Therac-25 смертельной дозой радиации были убиты 6-7 человек.
Причиной послужила неправильная работа с многопоточностью и возникший вследствие этого integer overflow (переполнение переменной int).
На эту тему есть отличное видео-эссе, которое я оставил в источниках.
Баги в видеоиграх
Очень много ошибок в видеоиграх, которые при желании очень легко нагуглить.
Наверное, самый легендарный пример - это сломанный экран в пакмане

Если играть достаточно долго, переменная с номер уровня переполняется, и экран уровня заполняется случайными символами, из-за которых пройти игру становится невозможно.
Справедливости ради должен отметить, что все эти примеры, мягко говоря, случились достаточно давно - но это не значит, что проблемы, описанные в этой статье, неактуальны.
Просто если их не учитывать, по уровню разработки вы откатитесь на 20-30 лет назад.
Источники
Литералы
Литералы - это специальные символы, которые мы можем использовать для более удобной записи кода, или для спецификации типа значения.
Литералы - это не переменные и не ключевые слова, это именно специальные символы.
Очевидное
Когда мы записываем какое-то число в переменную:
int a = 123;
...мы пользуемся целочисленным литералом. В данном примере мы используем целочисленный литерал 123.
С дробными числами, соответственно, используются литералы с плавающей точкой:
float pi = 3.14
То же самое относится к символам и строкам:
char a = 'A';
std::string b = "ABCDE";
Здесь мы используем строковые и символьные литералы.
Обознечение типа литералов
Логично, что целочисленные, символьные и прочие литералы обозначают значение, которое принадлежит к некому типу данных.
По умолчанию происходит так:
- Целочисленные литералы обозначают тип
int - Литералы с плавающей точкой обозначают тип
float - Символьные литералы обозначают тип
char - Для строковых литералов всё сложнее - они обозначают тип
char[], или же массив символов (char).
Про массивы будем подробнее говорить в следующих уроках.
Но что, если в нашем конкретном случае литерал должен обозначать другой тип? Для этого используются специальные суффиксы.
Думаю, самая критичная ситуация, в которой используются суффиксы - это для строковых и символьных литералов. Если для этих литералов не задать правильный суффикс, данные будут повреждены. Подробнее об этом будет далее.
Целые числа
unsigned int num6{ 1024U }; // U - unsigned int
long num7{ -2048L }; // L - long
unsigned long num8{ 2048UL }; // UL - unsigned long
long long num9{ -4096LL }; // LL - long long
unsigned long long num10{ 4096ULL };// ULL - unsigned long long
Символы и строки (суффиксы те же)
Частично этот синтаксис рассматривался в уроке про типы данных:
wchar_t w_ch = L'Д';
char8_t C1 = u8'a';
char16_t uc2 = u'¢'
char32_t Uc4 = U'🍌'
Почему для символьных и строковых литералов особенно важно указывать эти суффиксы? (далее буду говорить только про символы, чтобы просто не писать много текста - со строками всё то же самое).
Рассмотрим следующий код:
#include <iostream>
int main()
{
wchar_t wide_char = 'Д';
std::wcout << wide_char;
}
Вроде бы, здесь не происходит ничего ужасного. Но что означает запись 'Д'?
Как мы помним, символьные литералы по умолчанию воспринимаются как тип данных char. А в этом коде, мы вместо символа из ASCII-таблицы используем Д.
Когда компилятор будет разбирать этот код, он преобразует символ Д в какую-то последовательность бит в зависимости от кодировки самого файла с исходным кодом. В файле исходного кода же по сути тоже лежит текст, представленный в определённой кодировке.
И символ Д в итоге преобразуется в некоторое число бит, которое явно не поместится в один байт. Из-за этого компилятор "обрежет" эти биты и будет воспринимать как char только первые 8 бит.
Вследствие этого на экран в нашем примере выведется мусорное значение.
На самом деле компилятор по этому поводу даже выведет на экран предупреждение:
warning: multi-character character constant [-Wmultichar]
6 | wchar_t wide_char = 'Д';
Здесь компилятор предупреждает, что мы как будто указали в одинарных скобках больше, чем один символ - это происходит как раз из-за того, что символ Д занимает в памяти больше 8 бит.
Числа с плавающей точкой
float float_var = 3.14f;
double double_var = 3.14;
long double long_double_var = 3.14l;
Другие формы записи
Те же самые литералы (целочиселнные, строковые, ...) можно записывать в другом формате.
Разделение числа на разряды
При записи целого числа в любом месте между цифрами можно поставить '.
Так число можно сделать более читаемым:
int large_number = 1000000;
int million = 1'000'000;
То же самое можно использовать и для дробных чисел.
Научная нотация
Дробные числа можно записывать с помощью научной нотации:
double some_value = 4e2;
Запись 4e2 в математическом эквиваленте на самом деле просто обозначает \( 4 \times 10^2 \).
Разные системы счисления
Очень полезной может оказаться также запись числа в разных системах счисления.
Двоичная система счисления:
int binary_number = 0b10010010111;
Шестнадцатиричная система счисления:
int address = 0xFFF87AD;
В такой записи можно использовать те же привычные суффиксы и литералы:
int a = 0b11'01'10;
int b = 0b11001011UU;
Источники
- Докуметация C++ по целочисленным литералам
- Документация C++ по литералам с плавающей точкой
- Документация C++ по строковым литералам
- Документация C++ по символьным литералам
Константные данные
В С++ можно сделать так, чтобы значение переменной было неизменяемым. Делается это с помощью ключевого слова const.
Как и в случае с auto, такая переменная должна быть инициализирована сразу же при объявлении.
Пример
Предположим, в нашей программе пользователь выбирает один день в году, и нам нужно определить корректность введённых данных. А так же предположим, чтобы не возиться с ненужными деталями, что в нашем прекрасном мире не существует високосных годов:
int main()
{
const unsigned short days_in_year = 365;
std::cout << "Enter number of a day in the year\n";
int day; std::cin >> day;
if (day < 1 || day > days_in_year)
{
std::cout << "Invalid day\n";
return 1;
}
// какой-то код далее
}
Здесь мы определили переменную days_of_year, и сделали её константной. Это логично, ведь количество дней в году - это число, которое точно не поменяется во время выполнения программы, и было бы неприятно, если бы кто-то это значение случайно поменял.
Почему использовать литералы напрямую - плохо
В этом примере можно бы было сказать: а зачем нам вообще использовать какую-то константную переменную? Почему бы просто сразу не написать 365?
На это есть несколько весомых причин:
- При помощи констант повышается читаемость кода - сразу понятно, что мы сравниваем номер дня с количеством дней в году
- Если мы решим поменять значение константы (для нашего примера - если мы, например, захотим сделать программу для лунного календаря), то нам нужно будет его поменять только в одном месте (в месте инициализации переменной), а не во всех местах, где используется это значение.
- Зачастую константные значения банально неудобно много раз писать - если это, например, длинная строчка или большое число.
- Если мы ошибимся в написании имени константной переменной, компилятор сразу же поправит нас, но если мы вместо одного числа случайно напишем другое (то же самое касается и строк/символов), то компилятор не сможет определить эту ошибку.
Если использование строк или символов напрямую ещё не так плохо, то использование напрямую чисел уже может вызвать проблемы при чтении и отладке кода.
Наиболее наглядно можно увидеть эту проблему на таком коде:
draw(2, 320, 240, 3, 7);
Происходит вызов функции draw с абсолютно непонятными параметрами - понять, что реально происходит в этом коде, достаточно сложно.
Такие заданные напрямую целочисленные литералы или литералы с плавающей точкой называют магическими числами.
И глобальное правило написания хорошего кода можно выразить так: в коде вообще не должно быть никаких магических чисел; единственное исключения составляет число 0, и иногда 1.
Механизм работы const
Стоит понимать, что из себя по факту представляет ключевое слово const.
const - это просто подсказка для компилятора. Когда мы обозначаем переменную через const, мы просим компилятор проследить, чтобы никто не менял эту переменную, и всё.
Константность переменной никак не отражается на выходном коде.
Источники
Виртуальные функции [в разработке]
Отрывок с собеса на YouTube
Предположим, у нас есть класс Mammal:
class Mammal {
public:
void speak()
{
cout << "I'm Mammal\n";
}
};
И мы от него наследуем класс Cat:
class Cat : public Mammal {
public:
void speak()
{
cout << "Meow\n";
}
}
Предположим, что после всех этих операций, например, в функции main, мы запустим код:
Cat cat;
cat.speak();
В итоге у нас в консоль выведется строка Meow.
В данном случае мы сокрыли имя базового класса.
Если нам нужно будет запустить именно функцию из родительского класса, мы можем как-то переименовать функцию speak в классе Cat, ну или сделать так:
Cat cat;
cat.Mammal::speak();
Но в некоторых случаях нам нужно иметь доступ к полиморфизму.
Хочется обращаться к объекту через указатель на базовый класс, ну или через ссылку на базовый класс.
Например, было бы полезно иметь std::vector с объектами разных классов, унаследованных от класса Mammal (массив собак, кошек, и вообще кого угодно).
Если для текущего примера мы напишем следующий код:
unique_ptr<Mammal> cat = make_unique<Cat>();
cat->speak();
На экран будет выводится строка I'm Mammal.
Что происходит, когда в нашем нерабочем примере вызывается cat->speak()?
Во время выполнения программы рантайм видит, что просто происходит вызов функции speak() объекта класса Mammal. Происходит раннее связывание. Мы ранним связыванием связываем имя нашей функции с её адресом.
Чтобы наш код работал, нам и нужен механизм виртуальных функций.
Всё меняется, если мы добавляем ключевое слово virtual к объявлению функции speak в классе Mammal. Тут уже будет производиться позднее связывание, то есть связывание через указатель.
Для функции speak в дочернем классе можно дописать override: c С++11 это хорошая практика. Но вообще, если в родительском классе функция определена как virtual, то функция с таким же заголовком (хз правильно ли так говорит) в дочернем классе тоже автоматически будет виртуальной.
У каждого класса будет своя виртуальная таблица, в которой для каждой виртуальной функции будет записываться адрес этой функции.
Эту таблицу можно увидеть в дебаггере как отдельное поле void *vfptr (возможно тип не void, но сути не меняет).
Таким образом, для нашего примера, у классов Mammal и Cat будут созданы виртуальные таблицы, в которых для функции speak будут свои записи.
Когда мы проинициализируем указатель на Mammal как полиморфный класс типа Cat, в виртуальную таблицу класса Mammal, по аналогии с аргументом конструктора, будут записаны адреса функций для дочернего класса. И при выполнении тестового кода на экран будет выводиться уже Meow.
Чисто виртуальные функции
В общих чертах
Если мы не хотим, чтобы в родительском классе была реализация виртуальной функции, и хотим, чтобы все дочерние классы принудительно переопределяли её, мы можем использовать чисто виртуальные функции:
virtual void speak() = 0;
Класс с чисто виртуальной функцией будет называться абстрактным. Создавать объекты абстрактных классов запрещается (по понятным причинам).
Зачем нужны
- Определение интерфейса
- Предотвращение создания экземпляров базового класса
- Поддержка полиморфизма
pure virtual call
У нас могут быть проблемы, если мы в конструкторе абстрактного класса попытаемся вызвать чисто виртуа льную функцию: потому что на этапе выполнения кода ещё может просто "не создасться" дочерняя переопределённая функция, и произойдёт ошибка. Если попробовать вызвать чисто виртуальную функцию напрямую в конструкторе, нам даже не дадут скомпилировать программу. Но если это как-то спрятать от компилятора (например, вызвать чисто виртуальную функцию через другую функцию в конструкторе), то программа скомпилируется и произойдёт ошибка вызова чисто виртуальной функции (программа аварийно завершится). Проблема тут, опять же, в том, что конструктор базового (в данном случае абстрактного) класса вызовется раньше, чем конструктор дочернего класса. Отсюда и проблема с тем, что в виртуальной таблице класса функция будет ссылаться на какой-то мусор.
Зачем нужен виртуальный деструктор
easyoffer Нужен чтобы гарантрировать, что в дочернем классе, созданном полиморфно от родительского класса, будет вызван именно дочерний деструктор. Вызов цепочки деструкторов: Виртуальный деструктор гарантирует, что при удалении объекта через указатель на базовый класс сначала вызовется деструктор производного класса, а затем деструкторы всех базовых классов по цепочке наследования Виртуальный деструктор необходим, если:
- Вы работаете с наследованием и объектами базового класса могут быть расширены в производных классах.
- Вы удаляете объекты через указатель на базовый класс.
Просто так помечать деструктор в классе как virtual не надо.
Что такое виртуальное наследование?
easyoffer Владимир Балун Вообще, если полиморфно создавать от базового класса классы-наследники, то в каждом дочернем классе будет создан "внутри" родительский класс. Но что же происходит, если у нас происходит ромбовидное наследование?
flowchart TD subgraph SA direction LR A --> B A --> C B --> D C --> D end SA
В таком случае у нас по идее создался бы объект класса A внутри объектов классов B и C, и потом внутри класса D по объекту классов B и С. Какие же у такой ситуации проблемы?
- Два раза хранится один и тот же класс A
- Два раза будет вызываться конструктор и деструктор класса A Как избежать таких проблем? С помощью витруального наследования!
class B : virtual A {};
Что же будет тогда в памяти по классу D?
void *vbptr; // указатель класса B на родительский
int b_data;
void *vbptr; // указатель класса C на родительский
int c_data;
int d_data;
int a_data; // в самом конце класс на который ссылаются B и C
Лямбда выражения [в разработке]
Перевод в другую систему счисления
Представим, что строительная компания поставляет некие детали в разные страны. И в одной из программ в этой компании требуется ей перевести длины деталей из одной системы счисления в другую.
Взгляните на следующий пример кода:
#include <iostream>
#include <vector>
#include <algorithm>
float meters_to_feet(float meters)
{
return meters * 3.28084;
}
float meters_to_sm(float meters)
{
return meters * 100;
}
float meters_to_inches(float meters)
{
return meters * 39.3701;
}
int main()
{
std::vector <float> len_m = {1.84, 2.05, 2.09, 1.64};
std::vector <float> len_f(len_m.size());
std::vector <float> len_s(len_m.size());
std::vector <float> len_i(len_m.size());
std::transform(len_m.begin(), len_m.end(), len_f.begin(), meters_to_feet);
std::transform(len_m.begin(), len_m.end(), len_s.begin(), meters_to_sm);
std::transform(len_m.begin(), len_m.end(), len_i.begin(), meters_to_inches);
}
Здесь без использования лямбда-выражений производится перевод массива длин деталей в метрах в массивы длин деталей в футах, сантиметрах и дюймах. С помощью метода [[std transform|std::transform]] мы обрабатываем начальный массив заданными функциями и записываем результаты работы функции по каждому элементу начального массива в новый массив.
Как итог, мы получили громоздкий и тяжело читаемый код, с большим количеством повторяющихся однотипных функций. Ради одной функции, которая просто умножает float на коэффициент, приходится писать очень много лишнего кода.
На помощь приходят лямбда-выражения
Взглянем теперь как бы выглядел наш код с использованием лямбда-выражений:
#include <iostream>
#include <vector>
#include <algorithm>
template <typename T>
void print_vector(const std::vector<T> &vec)
{
for (const auto &x : vec)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}
int main()
{
std::vector <float> len_m = {1.84, 2.05, 2.09, 1.64};
std::vector <float> len_f(len_m.size());
std::vector <float> len_s(len_m.size());
std::vector <float> len_i(len_m.size());
std::transform(len_m.begin(), len_m.end(), len_f.begin(),
[](float m) {return m * 3.28084;});
std::transform(len_m.begin(), len_m.end(), len_s.begin(),
[](float m) {return m * 100;});
std::transform(len_m.begin(), len_m.end(), len_i.begin(),
[](float m) {return m * 39.3701;});
print_vector(len_f);
print_vector(len_s);
print_vector(len_i);
}
Нужные нам функции мы "определили" прямо в функции main! Код стал намного более читаемым, мы избавились от лишних и ненужных повторений.
Применяем для примера capture list
В нашем примере, все три используемых лямбды отличаются только коэффициентом, на который домножается m. Почему бы не вынести этот коэффициент как отдельную внешнюю переменную? Так можно достаточно стремительно расширить функционал программы и сделать её ещё более простой. Сделать это нам помогает capture-list лямбда выражения:
#include <iostream>
#include <vector>
#include <algorithm>
template <typename T>
void print_vector(const std::vector<T> &vec)
{
for (const auto &x : vec)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}
int main()
{
std::vector <float> len_m = {1.84, 2.05, 2.09, 1.64};
std::vector <float> len_f(len_m.size());
std::vector <float> len_s(len_m.size());
std::vector <float> len_i(len_m.size());
std::vector<std::pair<std::vector<float>, float>> coeff_to_vec
= {{len_f, 3.28084}, {len_s, 100}, {len_i, 39.3701}};
for (auto&& [vec, coeff] : coeff_to_vec)
{
std::transform
(
len_m.begin(),
len_m.end(),
vec.begin(),
[&coeff](float m) {return m * coeff;}
);
print_vector(vec);
}
}
В фигурных скобках для лямбда-выражения мы указываем, что лямбда-функция должна захватывать локальную переменную coeff и использовать её в своих вычислениях.
Как видим, код стал ещё понятнее и проще.
Ну а теперь поговорим более "официально" о том, что такое лямбда-выражение.
Теория
cppreference.com
Constructs a closure: an unnamed function object capable of capturing variables in scope.
Синтаксис лямбда-выражения:
[](){}
- В квадратных скобках указываются переменные для захвата
- В круглых скобках указываются аргументы лямбда-функции
- В фигурных скобках указывается само тело функции. Что значит "захватить" переменные? Это значит, что лямбда может в теле функции использовать переменные из локальной области видимости, если задать, что мы действительно хотим их в ней использовать. Захватить переменные можно несколькими способами:
[=]- захват лямбдлй всех локальных переменных по значению[&]- то же самое, но только по ссылке[this]- захват лямбдой текущего объекта класса (для методов класса). Так можно получить внутри лямбды доступ ко всем методам и полям класса[value1, &value2]- захват лямбдой конкретных переменных по значению/по ссылке (соответственно) Внутри лямбды можно обращаться к глобальным переменным/статическим переменным какого-либо класса/constexpr-переменным.
Дополнительные фишки
Можно явно задать тип возвращаемого лямбдой значения:
[](int a) -> int {return a + 3};
Можно так же получить из лямбды указатель на функцию:
+[](){}
Делается это с помощью + перед лямбдой.
Использование лямбды
- Можно объявить лямбду и сразу вызвать её:
[](){std::cout << "Hello world!\n";}();
2. Можно записать лямбду в локальную переменную:
```cpp
auto lambda = [](){std::cout << "Hello world!\n";};
lambda();
- Поддерживается каст лямбды в указатель на функцию:
void (*f_ptr)() = lambda; f_ptr();
4. Лямбду, как и любой другой callable объект, можно "записать" в `std::function`:
```cpp
std::function<void()> f = lambda;
- Переменную с лямбдой нельзя перезаписывать
Введение в GNU Autotools
Значительную часть по теории я взял из презентации
Alexandre Duret-Lutz. Все источники в конце страницы.
GNU Autotools - это набор из нескольких утилит (automake, autoreconf, ...), которые при совместном использовании предоставляют разработчику удобную среду для сборки, компиляции и распространения своих проектов.
Очень важной особенностью GNU Autotools является то, что они нацелены на поддержку и распространение проектов, написанных согласно стандарту GNU - см. GNU Coding Standarts. Но, конечно же, подчиняться всем правилам стандарта при использовании Autotools не обязательно (хотя от многих из них просто так уйти не получится).
Стоит также понимать, что GNU Autotools не зависят от конкретного языка программирования, и по аналогии с Make, представляют собой очень сложную надстройку над обычными скриптами командной оболочки. С помощью Autotools можно собирать проекты как на C, так и на C++, Python, C#, и так далее.
Зачем нам нужны Autotools
Входные условия
Предположим, у нас есть некоторый проект на C/C++, и мы хотим, чтобы пользователи на разных машинах могли собрать его.
Поэтому мы решаем поставлять наш проект в формате исходного кода, который потом должен быть скомпилирован на целевом устройстве.
С портированием проекта на другие системы есть множество проблем:
- На разных машинах могут быть процессоры разной архитектуры (RISC-V, ARM, x64, ...) и разной разрядности
- На разных машинах могут быть разные ОС
- На разных машинах могут быть установлены разные компиляторы, разных версий и с разными реализациями рантайма (
clang,msvc,gcc,musl, ...)
Кроме того, существуют проблемы касательно самого исходного кода, даже на уровне совершенно стандартных операций (на примере языка C):
- Некоторые стандартные функции есть не на всех системах (
strtod) - У некоторых стандартных функций на разных системах могут быть разные названия (
strchr()иindex()) - У стандартных функций на разных системах могут быть разные прототипы (
setpgrp(void)иsetpgrp(int, int)) - Стандартные функции на разных системах могут вести себя по-разному (например, вызов
malloc(0)) - Стандартные функции могут быть определены в разных разделяемых библиотеках (например, для математических функций -
libm.soиlibc.so) - Стандартные функции могут быть объявлены в разных заголовках (
string.h,strings.h,memory.h) И плюс к этому, проект может использовать сторонние зависимости, которые тоже в свою очередь по реализации могу отличаться на разных системах. Самый банальный пример - это работа с графикой через API конкретной платформы.
Нам, как разработчикам, нужно разобраться, как со всем этим работать
Примитивные решения
1. Заполнение кода директивами #if/#else
#if !defined (CODE_EXECUTABLE)
static long pagesize = 0;
#if defined (EXECUTABLE_VIA_MMAP_DEVZERO)
static int zero_fd ;
#endif
if (! pagesize)
{
#if defined (HAVE_MACH_VM)
pagesize = vm page size ;
#else
pagesize = getpagesize ();
#endif
#if defined (EXECUTABLE_VIA_MMAP_DEVZERO)
zero_fd = open ("/dev/zero", O_RDONLY, 0644) ;
if (zero_fd < 0)
{
fprintf (stderr, "trampoline: Cannot open /dev/zero! \n") ;
abort() ;
}
#endif
}
#endif
Такой код:
- неудобно читать
- неудобно изменять
- неудобно поддерживать
В процессе написания программы, вместо мыслей о реальной логике программы, мы будем заняты написанием повторяющегося неаккуратного кода для учёта мелких незначительных деталей разработки под конкретную систему.
2. Макросы для замены кода
Если на целевой платформе нет нужной нам функции, мы могли бы определить её через макрос:
#if ! HAVE_FSEEKO && ! defined fseeko
#define fseeko(s, o, w) ((o) == (long)(o) \
? fseek(s, o, w) \
: (errno = EOVERFLOW, -1))
#endif
Но определять через макросы каждую функцию было бы ужасно утомительно. Да и в целом использовать такие макросы это не очень хорошая практика.
3. Ручная замена функций
Если какой-то функции нет на целевой платформе, мы могли бы сами в отдельном файле переписывать эту функцию и линковать её с основной программой.
char* strdup(const char *s)
{
sizt_t len = strlen(s) + 1;
void* new = malloc(len);
if (new == NULL)
{
return NULL;
}
return char* memcpy(new, s, len);
}
Пару слов про Make
Как первый шаг к решению этих проблем разберём использование утилиты make и проблемы, которые она решает.
Сборка без Make
Напрямую, чтобы собрать программу, нам нужно запустить компилятор для каждого "модуля" этой программы и получить для него готовый объектный файл, и потом объектные файлы объединялись бы с помощью линковщика в готовую программу. Конечно же, эта схема сильно упрощена, но суть примерно такая.
Чтобы напрямую при помощи командной строки собрать даже небольшой проект из трёх компонентов, нужно писать очень много текста:
g++ -c 1.cpp
g++ -c 2.cpp
g++ -c 3.cpp
g++ -c main.cpp
g++ 1.o 2.o 3.o main.o -o main
./main
И это мы ещё не писали каких-то аргументов для компилятора и для сборщика, не подключали сторонние библиотеки и вообще - собрали маленький простенький проект.
Вы можете возразить, что весь этот код можно просто записать в shell-скрипт и не прописывать его каждый раз:
sh compile.sh
./main
И это, конечно, делает жизнь чуть легче.
Но что, если из огромного проекта на сотни объектных файлов нам потребовалось поменять только две строчки кода? Тогда нам придётся, если использовать единый скрипт, перекомпилировать весь проект ради одного небольшого изменения.
Конечно, можно написать отдельный скрипт для линковки, и отдельный скрипт для компиляции каждого отдельного файла... Но тогда нам придётся при каждой новой компиляции чётко помнить, какие объектные файлы нужно пересобирать, и по итогу, мы не сильно уйдём от начальной структуры, где мы для каждого файла отдельно прописывали команды компиляции.
Есть и другие проблемы при использовании самописных shell-скриптов:
- Отсутствие единого стандарта: каждый пишет, как он хочет
- Много лишней повторяющейся работы
- Невозможность запустить компиляцию целевой программы в несколько потоков
- ...
Использование Make
Описанные выше проблемы помогает решить утилита make, разработанная ещё в 1978 году.
Утилита make позволяет с помощью унифицированного синтаксиса записывать правила сборки больших проектов.
Правила сборки для make записываются в специальном файле Makefile.
Makefile для нашего синтетического примера выглядел бы примерно так:
1.o : 1.cpp
g++ -c 1.cpp
2.o: 2.cpp
g++ -c 2.cpp
3.o : 3.cpp
g++ -c 3.cpp
main.o : main.cpp
g++ -c main.cpp
main: 1.o 2.o 3.o main.o
g++ 1.o 2.o 3.o main.o -o main
Стоит отметить, что этот Makefile не очень аккуратный, и вообще-то, так писать лучше не стоит. Но мы его рассматриваем чисто для примера.
Что же здесь записано?
Как видим, сначала тут прописываются цели сборки, потом прописываются файлы/другие цели сборки, необходимые для этой, и сама команда сборки:
цель_сборки: зависимость_1 зависимость_2 ...
команда_для_сборки
команда_для_сборки - это обычная команда для выполнения в командной оболочке (bash, fish, ...).
Чтобы выполнить команду для сборки определённой цели, нужно вызвать команду make, и как аргумент передать название цели:
make 1.o
При таком вызове будет выполнена команда g++ -c 1.cpp, и сгенерируется файл 1.o
Если же прописать:
make main
Утилита make увидит, что для цели main ей нужно собрать цели 1.o, 2.o, 3.o, main.o - и она в указанном порядке выполнит их. И только после этого будет выполнена команда для main.
Как итог, "под капотом" будут выполнены те же команды, которые были прописаны вручную ранее, но в данном случае вместо ручного прописывания всех команд мы выполняем всего один простой вызов make.
Кроме того, утилита make отслеживает дату изменения файлов, используемых при сборке. И поэтому, если мы изменим в проекте только один файл, make отследит этот момент и пересоберёт только цель, связанную с этим одним файлом, а не весь проект целиком.
Вообще, в целом, утилита make - это чуть более удобная обёртка над теми же shell-скриптами. С помощью make можно выполнять вообще любые команды, например, можно вывести на экран Hello World:
hello_world:
echo "Hello World"
make hello_world
...+ ко всему перечисленному, в Makefile можно определять локальные переменные, можно использовать переменные окружения, оставлять специальные параметры сборки, и т.д. и т.п.
Пример сложного и хорошо записанного Makefile можно посмотреть здесь.
Также частой практикой является создание в проекте "вложенных" Makefile-ов: один главный Makefile, которые генерирует готовое решение, вызывает make для других, "вложенных" Makefile-ов, которые собирают отдельные компоненты программ. Так можно разделить логику сборки проекта целиком и его отдельных частей.
Стандартные цели сборки Make
Так как make можно использовать не только для непосредственно компиляции программы, но и вообще в принципе для чего угодно, с помощью make зачастую задают и инструкции для установки программы в системе (см. Unix-утилиту install), для очистки сборочных файлов, для деинсталляции пакета из системы, и так далее.
В основном, определяют следующие стандартные цели:
make all- сборка программ, библиотек, документации, ...make install- установка чего-либоmake uninstall- деинсталляция чего-либоmake clean- стереть всё, что было собрано (противоположностьmake all)make check- запустить тесты, если такие естьmake install check- проверить установленные программы или библиотеки, если это поддерживаетсяmake dist- создатьPACKAGE-VERSION.tar.gz-tar-архив с файлами проекта для установки на конкретной системе
Если вызвать make без указания цели, выполняется цель all.
Почему Make недостаточно
Конечно, make значительно упрощает процесс сборки программ по сравнению с использованием обычных shell-скриптов. Но те же самые проблемы, которые были озвучены ранее, остаются и с использованием make:
- Различие версий компиляторов и библиотек на разных системах
- В принципе разные компиляторы на разных системах
- Отличающиеся флаги и аргументы компилятора на разных машинах
- Проблемы с самим исходным кодом, перечисленные ранее
- и т.д.
Таким образом, если при компиляции и сборке проекта ограничиться только использованием make, мы значительно упростим процесс сборки программы, но всё равно нам пришлось бы заставлять пользователей программы вручную менять скрипты в Makefile и, возможно, даже менять что-то в самом исходном коде.
Скрипт configure
В какой-то момент, для решения вышеприведённых проблем, стандартным решением стал скрипт configure - разработчики вручную писали скрипт, который сканировал систему, определял её основные параметры, искал системные заголовки, библиотеки и прочее, и на основе этого генерировал Makefile, из которого уже собирался и устанавливался требуемый пакет.
Со временем, чтобы как-то унифицировать процесс сборки различных программ, было принято решение стандартизировать API скрипта и его схему работы. Далее рассмотрим то, как же он функционирует на практике.
...на выходе configure генерирует несколько файлов:
configure.h- файл со всеми необходимыми включениями библиотек и дефайнамиMakefile-Makefileдля сборки всего проекта под конкретную платформуsrc/Makefile- вложенныеMakefileы для отдельных компонентов
flowchart TD A["configure"] --> B["Makefile"] A --> C["src/Makefile"] A --> D["configure.h"] classDef utility fill:yellow,color:black classDef finalfile fill:black,color:white class A utility class B finalfile class C finalfile class D finalfile
И вот так выглядит типичный процесс установки программы с использованием make и configure:
tar zxf helloworld-1.0.tar.gz # распаковываем архив с исходниками
cd helloworld-1.0 # переходим в папку с исходниками
./configure # запуск скрипта configure
make # компилируем и собираем проект
make check # проверяем, собралось ли всё правильно
sudo make install # устанавливаем собранный проект в систему
make installcheck # проверяем корректность устновки
Базовый процесс установки
Файловая иерархия
Наш проект следует установить где-то в системе, а если это библиотека, нужно ещё и в какую-то локацию положить динамические/статические либы и заголовочные файлы.
Учитывая все эти сложности, скрипт должен понимать, как эти папки и файлы располагаются в системе и как они зависят друг от друга.
| Переменная | Значение по умолчанию |
|---|---|
| prefix | /usr/local/ |
| exec-prefix | prefix |
| bindir | prefix/bin |
| libdir | prefix/lib |
| includedir | prefix/include |
| datarootdir | prefix/share |
| datadir | datarootdir |
| mandir | datarootdir/man |
| infodir | datarootdir/info |
Пример конфигурации проекта, который использует папки, отличные от папок по умолчанию:
./configure --prefix ~/usr
make
make install
Задание флагов сборки
configure в своей работе использует много настроек, и мы можем вручную поменять некоторые из них.
| Флаг | Описание |
|---|---|
| CC | Компилятор для C |
| CFLAGS | Флаги компиляции для C |
| CXX | Компилятор для C++ |
| CXXFLAGS | Флаги компиляции для C++ |
| LDFLAGS | Флаги для линковщика |
| CPPFLAGS | Флаги препроцессора C/C++ |
Пример конфигурации проекта с заданием кастомных флагов:
./configure --prefix ~/usr CC=gcc-3 CPPFLAGS=-I$HOME/usr/include LDFLAGS=-L$HOME/usr/lib
На самом деле, это конечно же не все возможные настройки для скрипта. Перечень всех доступных настроек выводится через ./configure --help.
Более сложные параметры сборки
Вынесение настроек конфигурации в отдельный файл
Можно вынести настройки конфигурации в отдельный файл, чтобы каждый раз не прописывать длинную очередь команд.
configure.site:
test -z "$CC" && CC=gcc-3
test -z "$CPPFLAGS" && CPPFLAGS = -I$HOME/usr/include
test -z "$LDFLAGS"&& LDFLAGS=-L$HOME/usr/lib
Итоговый запуск сборки:
./configure --prefix=~/usr
И в выводе скрипта увидим строчку:
configure: loading site script /home/dmitriy/usr/share/config.site
Отделение папки сборки и папки с исходниками
mkdir build && cd build
../configure
make
Исходный код будет записан в /helloworld-1.0, а файлы сборки в /helloworld-1.0/build/.
Сборка под разные архитектуры
Из одних и тех же исходников возможно собрать проект под несколько архитектур.
Извлечение исходников:
cd /nfs/src
tar zxf ~/helloworld-1.0-tar.gz
Сборка на конкретной платформе:
mkdir /tmp/hw && cd /tmp/hw
/nfs/src/helloworld-1.0/configure
make && sudo make install
Либо же, может быть запущен make install-exec, если две системы разделяют одни и те же данные
Двухуровневая установка
Цель make install на самом деле использует внутри следующие цели:
make install-exec- установка файлов, зависящих от конкретной платформы (разделяемые библиотеки, исполняемые файлы, ...)make install-data- установка платформенно независимых файлов - файлов, которые могут быть расшарены на несколько машин (например, документация, илиman pages)
Кросс-компиляция
Опция, с помощью которой можно на машине с одной архитектурой и платформой собрать проект под совершенно другую архитектуру и платформу (например, на 64-битной Linux-машине собрать проект для 32-битной Windows машины). Конечно же, подразумевается, что на машине уже установлен кросс-компилятор
Пример кросс-компиляции:
./configure --build=i686-pc-linux-gnu --host=i586-mingw-32msvc
make
cd src; file helloworld.exe
Опции для кросс-компиляции:
| Опция | Описание |
|---|---|
--build=BUILD | Система, на которой собирается проект |
--host=HOST | Система, под которую собирается проект |
Переименовывание программы во время установки
Что, если программа с заданными нами именем уже существует в системе? Было бы неплохо предусмотреть подобный сценарий чтобы случайно не перезаписать существующее ПО.
Опции скрипта configure для переименовывания при установке:
| Опция | Описание |
|---|---|
--program-prefix=PREFIX | Добавить префикс к имени программы |
--program-suffix=SUFFIX | ........ суффикс ................. |
--program-transform-name=PROGRAM | Заменить имена установленных программ на PROGRAM через sed |
Установка проекта как пакета
Можно собрать пакет в готовый tar.gz архив и потом использовать его для распаковки на целевой машине.
DESTDIR используется чтобы перенести пакет во время установки.
./configure --prefix ~/usr
make
make DESTDIR=$HOME/inst install
...
cd ~/inst
tar zcvf ~/helloworld-1.0-i686.tar.gz .
Итоговый алгоритм работы configure
Упрощённый
flowchart TD A["Makefile.in"] --> B["configure"] C["src/Makefile.in"] --> B D["config.h.in"] --> B B --> E["Makefile"] B --> F["src/Makefile"] B --> G["config.h"] classDef configfile fill:orange,color:black classDef configutil fill:yellow,color:black classDef finalfile fill:black,color:white class A configfile class C configfile class D configfile class E finalfile class F finalfile class G finalfile class B configutil
*.in - это файлы-шаблоны, которые скрипт configure использует для генерации готовых конфигурационных файлов Makefile, src/Makefile, config.h
Реальный
flowchart LR A["Makefile.in"] --> F C["src/Makefile.in"] --> F D["config.h.in"] --> F B["configure"] --> E["config.log"] B --> F["config.status"] F --> G["Makefile"] F --> H["src/Makefile"] F --> I["config.h"] F --> E B --> J["config.cache"] J --> B classDef configfile fill:orange,color:black classDef configutil fill:yellow,color:black classDef configtemp fill:brown,color:black classDef finalfile fill:black,color:white class A configfile class C configfile class D configfile class G finalfile class H finalfile class I finalfile class B configutil class F configutil class J configtemp class E configtemp
- В
config.logхранится лог процесса конфигурации - Фактически обрабатывает шаблонные файлы
config.status - В файле
config.cacheхраним кэш конфигурации для более быстрой переконфигурации проекта. Генерируется командойconfigure -C
Вывод: зачем нам нужны Autotools
Как легко заметить, выше мы рассмотрели огромное число достаточно сложных для реализации функций. Даже если мы не хотим придерживаться чёткого конкретного стандарта разработки от GNU, всё равно весь перечисленный функционал, в той или иной форме, должен быть доступен пользователю для сборки вашего проекта.
Представьте, что реализацию кросс-компиляции, чтения файла настроек, обнаружение компилятора в системе с проверкой его версии и с учётом запуска скрипта на разных ОС, ... - что всё это нам пришлось бы писать самостоятельно. Очевидно, мы натыкаемся на огромное число велосипедов, которые делать будет долго и сложно.
Плюс со временем общий стандарт работы систем сборки может изменяться, могут появляться новые требования к процессу сборки от пользователей вашего программного продукта.
Да и к тому же, какой-то функционал, который может быть критически важен для некоторых пользователей, вы можете просто не рассмотреть в своей реализации configure.
GNU Autotools представляют готовое, оптимизированное и оттестированное решение, которое периодически обновляется и улучшается и которое уже поддерживает весь необходимый функционал.
GNU Autotools
Hello World
Готовое решение
Создадим базовый проект Hello World, чтобы продемонстрировать возможности GNU Autotools, и далее обсудим, что здесь происходит.
Структура проекта:
- src/
- - main.cpp
- - Makefile.am
- configure.ac
- Makefile.am
src/main.cpp:
#include <config.h>
#include <iostream>
int main(void)
{
std::cout << "Hello World!\n";
std::cout << "This is " << PACKAGE_STRING << " .\n";
}
Программа выводит строчку Hello World! и название пакета.
src/Makefile.am:
bin_PROGRAMS = helloworld
helloworld_SOURCES = main.cpp
configure.ac:
AC_INIT([helloworld], [1.0], [example@mail.com])
AM_INIT_AUTOMAKE([foreign -Wall -Werror])
AC_PROG_CXX
AC_CONFIG_HEADERS([config.h])
AC_CONFIG_FILES([Makefile src/Makefile])
AC_OUTPUT
Makefile.am:
SUBDIRS=src
Подготовка скрипта configure:
autoreconf --install
Вывод:
configure.ac:2: installing './install-sh'
configure.ac:2: installing './missing'
src/Makefile.am: installing './depcomp'
Итоговая структура проекта:
- alocal.m4
- autom4te.cache/
- config.h.in
- configure
- configure.ac
- depcomp
- install-sh
- Makefile.am
- Makefile.in
- missing
- src/
- - main.cpp
- - Makefile.am
- - Makefile.in
Запуск скрипта configure:
./configure
Вывод:
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking for g++... g++
checking whether the C++ compiler works... yes
checking for C++ compiler default output file name... a.out
checking for suffix of executables...
checking whether we are cross compiling... no
checking for suffix of object files... o
checking whether we are using the GNU C++ compiler... yes
checking whether g++ accepts -g... yes
checking whether make supports the include directive... yes (GNU style)
checking dependency style of g++... gcc3
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating Makefile
config.status: creating src/Makefile
config.status: creating config.h
config.status: executing depfiles commands
Сборка программы:
make
Вывод:
(CDPATH="${ZSH_VERSION+.}:" && cd . && /bin/sh /home/admin1/dev/autotools-test/missing autoheader)
rm -f stamp-h1
touch config.h.in
cd . && /bin/sh ./config.status config.h
config.status: creating config.h
config.status: config.h is unchanged
make all-recursive
make[1]: вход в каталог «/home/admin1/dev/autotools-test»
Making all in src
make[2]: вход в каталог «/home/admin1/dev/autotools-test/src»
g++ -DHAVE_CONFIG_H -I. -I.. -g -O2 -MT main.o -MD -MP -MF .deps/main.Tpo -c -o main.o main.cpp
mv -f .deps/main.Tpo .deps/main.Po
g++ -g -O2 -o helloworld main.o
make[2]: выход из каталога «/home/admin1/dev/autotools-test/src»
make[2]: вход в каталог «/home/admin1/dev/autotools-test»
make[2]: выход из каталога «/home/admin1/dev/autotools-test»
make[1]: выход из каталога «/home/admin1/dev/autotools-test»
Запуск готовой программы:
src/helloworld
Вывод:
Hello World!
This is helloworld 1.0
Сборка пакета tar.gz с проверкой корректности:
make distcheck
Вывод: (сокращён из-за большого объёма):
make dist-gzip am__post_remove_distdir='@:'
make[1]: вход в каталог «/home/admin1/dev/autotools-test»
...
================================================
helloworld-1.0 archives ready for distribution:
helloworld-1.0.tar.gz
================================================
Распаковка получившегося пакета на целевой системе:
tar ztf helloworld-1.0.tar.gz
Алгоритм работы
В данном примере мы используем утилиту autoreconf для того, чтобы сгенерировать скрипт configure и его "входные" файлы (Makefile.in, src/Makefile.in, config.h.in).
Таким образом, получаем следующую схему сборки нашего проекта:
flowchart LR L["configure.ac"] --> K M["Makefile.am"] --> K N["src/Makefile.am"] --> K K["autoreconf"] --> A K --> C K --> D K --> B A["Makefile.in"] --> F C["src/Makefile.in"] --> F D["config.h.in"] --> F B["configure"] --> E["config.log"] B --> F["config.status"] F --> G["Makefile"] F --> H["src/Makefile"] F --> I["config.h"] F --> E B --> J["config.cache"] J --> B classDef autotools fill:green,color:black classDef utility fill:red,color:black classDef configfile fill:orange,color:black classDef configutil fill:yellow,color:black classDef configtemp fill:brown,color:black classDef finalfile fill:black,color:white class A configfile class C configfile class D configfile class G finalfile class H finalfile class I finalfile class B configutil class F configutil class J configtemp class E configtemp class L autotools class M autotools class N autotools class K utility
Сгенерированные файлы
Makefile.in,configure.h.in,src/Makefile.in- шаблонные файлы для настройки конфигурацииconfigure- сам скрипт конфигурацииalocal.m4- определения для сторонних макросов, используемых вconfigure.acdepcomp,install-sh,missing- вспомогательные инструменты, которые используются во время сборкиautom4te.cache- кэш, сгенерированныйAutotools
Состав Autotools
На самом деле, autoreconf - это не единственная утилита Autotools, которая была нами использована в процессе сборки.
Рассмотрим примерное устройство GNU Autotools:
flowchart LR a["GNU Autotools"] --> b["GNU Autoconf"] a --> c["GNU Automake"] b --> d["autoconf"] b --> e["autoheader"] b --> f["autoreconf"] b --> g["autoscan"] b --> h["autoupdate"] b --> i["ifnames"] b --> j["autom4te"] c --> k["automake"] c --> l["aclocal"]
GNU Autocnf
autoconf- Создаёт скриптconfigureиз конфигаconfigure.acautoheader- Создаётconfigure.h.inизconfigure.acautoreconf- Запускает все утилиты в нужном порядкеautoscan- Проверяет исходники на возможные проблемы, связанные с переносимостью проекта на другие устройства, а также проверяет отсутствие соответствующих макросов вconfigure.acautoupdate- Обновляет устаревшие макросы вconfigure.acifnmaes- Собирает идентификаторы на основе всех директив#if/#ifdefautom4te- Основной инструментAutotools. Он отвечает за запускM4и реализовывает фичи, которые используют все остальные инструменты. Может быть использовано не только для созданияconfigureскрипта.
GNU Automake
automake- создаёт шаблоныMakefile.inна основеMakefile.amиconfigure.acaclocal- проверяетconfigure.acна использование сторонних макросов, и собирает их определения изalocal.m4
Таким образом, конечная реальная схема будет выглядеть так:
flowchart TD K["configure.ac"] --> L["aclocal"] L --> M["alocal.m4"] N["autoconf"] --> B K --> N M --> N O["autoheader"] --> D M --> O K --> O P["automake"] --> A P --> C Q["Makefile.am"] --> P R["src/Makefile.am"] --> P M --> P K --> P A["Makefile.in"] --> F C["src/Makefile.in"] --> F D["config.h.in"] --> F B["configure"] --> E["config.log"] B --> F["config.status"] F --> G["Makefile"] F --> H["src/Makefile"] F --> I["config.h"] F --> E B --> J["config.cache"] J --> B classDef autotools fill:green,color:black classDef utility fill:red,color:black classDef configfile fill:orange,color:black classDef configutil fill:yellow,color:black classDef configtemp fill:brown,color:black classDef finalfile fill:black,color:white class K autotools class Q autotools class R autotools class L utility class N utility class O utility class P utility class A configfile class C configfile class D configfile class B configutil class F configutil class J configtemp class E configtemp class G finalfile class H finalfile class I finalfile
- Зелёный - файлы конфигурации для
Automake - Красный - утилиты
Autotools - Оранжевый - шаблонные файлы для скрипта
configure - Жёлтый - скрипты конфигурации сборки (
configureиconfig.status) - Коричневый - вспомогательные файлы для конфигурации сборки
- Чёрный - итоговые файлы для сборки проекта на целевой машине
Почему мы используем autoreconf
- Не нужно запоминать чёткую последовательность и правила взаимодействия всех утилит внутри
Autotools - Для начальной настройки пакета используется только
autoreconf --install - Для сборки нужно только примерно понимать, за что отвечает та или иная утилита из
Autotools, чтобы понимать сгенерированные ошибки
configure.ac
Разберём ключевой конфиг autoconf (configure.ac) по строчкам.
AC_INIT([helloworld], [1.0], [example@mail.com])
Здесь мы инициализируем работу с autoconf командой AC_INIT. В неё мы передаём аргументы, которые обозначают название пакета, версию пакета и email для багрепортов.
Обратите внимание, что для определения строчек используются квадратные скобки, вместо кавычек
AM_INIT_AUTOMAKE([foreign -Wall -Werror])
Здесь мы инициализируем работу с automake. Внутри мы передаём аргументы для компиляции, а также задаём для пакета параметр foreign.
Слово foreign относится как раз к стандартам написания кода от проекта GNU. Когда мы задаём для пакета свойство foreign, мы говорим, что не хотим полностью подчиняться этому стандарту. Если бы мы не прописали foreign, после запуска autoreconf --install, automake выдал бы нам следующие ошибки:
Makefile.am: error: required file './NEWS' not found
Makefile.am: error: required file './README' not found
Makefile.am: error: required file './AUTHORS' not found
Makefile.am: error: required file './ChangeLog' not found
Makefile.am: installing './COPYING' using GNU General Public License v3 file
Makefile.am: Consider adding the COPYING file to the version control system
Makefile.am: for your code, to avoid questions about which license your project uses
Запуск завершается с ошибкой из-за того, что мы не оформили проект по всем правилам: не добавили файл со списком изменений, не добавили файл со списком авторов пакета, и т.д. и т.п.
-Wall и -Werror же - это просто флаги для компилятора, которые включают вывод всех возможных предупреждений и затем превращают все предупреждения в ошибки.
AC_PROG_CXX
Ищет в системе компилятор для C++.
AC_CONFIG_HEADERS([config.h])
Заявляем, что нам нужно сгенерировать выходной хэдер config.h
AC_CONFIG_FILES([Makefile src/Makefile])
Определяем выходные конфигурационные файлы Makefile и src/Makefile
AC_OUTPUT
Создаём все определённые в конфиге выходные файлы
Makefile.am
SUBDIRS = src
Говорим, что в папке src есть ещё файлы конфигурации Makefile.am
Для главной папки больше ничего не определили. В основном Makefile будет просто комбинация Makefile-ов из папки src.
Обычно корневые Makefile-ы всегда достаточно короткие, так что всё нормально
src/Makefile.am
bin_PROGRAMS = helloworld
_PROGRAMS- вы собираем какие-то программыbin- эти программы будут собраны вbindir(вспоминаем файловую иерархию проекта)- Мы будем собирать только одну программу:
helloworld
helloworld_SOURCES = main.cpp
Для того, чтобы собрать helloworld, нужно просто скомпилировать main.cpp
Использование Autoconf
По сути, autoconf - это просто преобразователь макросов.
configure.ac - это, на самом деле, просто shell-скрипт, которые использует макросы. autoconf обрабатывает эти макросы и на основе их составляет скрипт configure. Но configure.ac, состоящий только из встроенных макросов - это абсолютно нормальное явление.
autoconf предоставляет большое количество встроенных макросов для стандартных операций сборки и проверки конфигурации.
На самом деле, непосредственно сами макросы обрабатывает M4 - специальная программа-обработчик макросов, которую тоже поставляет проект GNU. autoconf представляет только надстройку над M4, + список предопределённых макросов.
Принцип работы M4
m4_define(NAME1, Harry)
m4_define(NAME2, Sally)
m4_define(MET, $1 met $2)
MET(NAME1, NAME2)
Вот так выглядит типичное объявление и использование макросов M4. В данном случае, MET(NAME1, NAME2) будет преобразовано в "Harry met Sally". Так же стоит учитывать, что для того, чтобы не обрабатывать какое-то слово или строку, или чтобы использовать в качестве одного слова строку с пробелами, следует использовать кавычки:
m4_define('NAME1', 'Harry, Jr.')
m4_define('NAME2', 'Sally')
m4_define('MET', '$1 met $2')
MET('NAME1', 'NAME2')
Данный код будет работать правильно, и с генерирует строчку Harry, Jr. met Sally
Следующий же код выдаст неправильную строку (точнее не ту, которую мы от него ожидаем):
m4_define(NAME1, 'Harry, Jr.')
m4_define(NAME2, Sally)
m4_define(MET, $1 met $2)
MET(NAME1, NAME2)
Как будет выполняться замена макросов в данной случае?
- Запомнили, что NAME1 -> 'Harry, Jr.'
- Запомнили, что NAME2 -> Sally
- Запомнили, что MET -> $1 met $2
- Встретили макрос MET, который принимает NAME1 и NAME2
- Заменили NAME1 на 'Harry, Jr.'. Получили MET(Harry, Jr., NAME2)
- Заменили NAME2 на Sally, получили MET(Harry, Jr., Sally)
- Заменили MET(Harry, Jr., Sally) на первый аргумент макроса + "met" + второй аргумент макроса, получили "Harry met Jr."
Autoconf как надстройка над M4
- В отличии от M4 в
autoconf, как отмечалось ранее, для обозначения строк используются квадратные скобки вместо кавычек - В следствие первого пункта, для условий в скрипте
configure.acмы используем вместо квадратных скобок словоtest:
if ["$x" = "$y"]; then ... # Привычный синтаксиси
if test "$x" = "$y"; then ... # Синтаксис autoconf
- Макросы в Autoconf определяются при помощи
AC_DEFUN:
AC_DEFUN([NAME1], [Harry])
Структура файла configure.ac
Обычно файл configure.ac записывают согласно предопределённому порядку выполнения команд:
- Первоначальная настройка -
AC_INIT,AM_INIT_AUTOMAKE - Проверки на наличие программ -
AC_PROG_CC,AC_PROG_CXX - Проверки на наличие библиотек
- Проверки на наличие заголовочных файлов
- Проверки на
typedef-ы, структуры и характеристики компилятора - Проверки библиотечных функций
- Определение результирующих файлов (
AC_CONFIG_HEADERS,AC_CONFIG_FILES,AC_OUTPUT)
Макросы для первоначальной настройки
AC_INIT(PACKAGE, VERSION, BUG-REPORT-ADDRESS)- обязательная инициализация AutoconfAC_PREREQ(VERSION)- определение минимальной возможной версии AutoconfAC_CONFIG_SRCDIR(FILE)- макрос для проверки того, чтоautoconfзапущен из правильной директории. Например,AC_CONFIG_SSRCDIR([src/main.c])- если из текущей директории не получится открытьsrc/main.c, выведется ошибка.AC_CONFIG_AUX_DIR(FOLDER)- все вспомогательные файлы для сборки (depcomp,missing, ...) должны быть расположены в папкеFOLDER- ...
Макросы для проверки наличия программ
AC_PROG_CC,AC_PROG_CXX,AC_PROG_F77- поиск компиляторов в системе (можно также найти кросс-компиляторы, при необходимости)AC_PROG_SED,AC_PROG_LEX, ... - поиск наиболее подходящих реализаций программ (sed,lex, ...) в системеAC_CHECK_PROGS(VAR, PROGS, [VAL-IF-NOT-FOUND])- ищет перечисленные программы в системе, и записывает найденные программы вVAR. Если какая-то программа не будет найдена, запишет вVARзначениеVAL-IF-NOT-FOUND. Пример использования:
AC_CHECK_PROGS([TAR], [tar gtar], [:])
if test "$TAR" = :; then
AC_MSG_ERROR([This package needs tar])
fi
Ищем в системе утилиту tar, и если не нашли, выводим ошибку
- ...
Макросы действий Autoconf
AC_MSG_ERROR(ERROR-DESCRIPTION, [EXIT-STATUS])- Печатает на экран ошибкуERROR-DESCRIPTIONи завершает скриптconfigureсо статусом ошибки[EXIT-STATUS]AC_MSG_WARN- то же, что и сERROR, но только без аварийного выходаAC_DEFINE(VARIABLE, VALUE, DESCRIPTION)- печатает в выходномconfig.hфайле следующее:
/* DESCRIPTION */
#define VARIABLE VALUE
AC_SUBST(VARIABLE, VALUE)- определяет переменную в результирующемMakefile-е:- ...
Макросы для проверки на наличие библиотек
AC_CHECK_LIB(LIBRARY, FUNCT, [ACT-IF-FOUND], [ACT-IF-NOT])- проверяет, существует ли библиотекаLIBRARYс определённой в нейFUNCT. Пример использования:
AC_CHECK_LIB([efence], [malloc], [EFENCELIB=-lefence])
AC_SUBST([EFENCELIB])
...здесь мы будем далее для линковки использовать $(EFENCELIB)
Если "действие при нахождении библиотеки" не будет определено, autoconf сделает LIBS=-lLIBRARY $LIBS и #define HAV_LIBLIBRARY. (automake использует для линковки всех библиотек $LIBS)
- ...
Макросы для проверки наличия заголовков в системе
AC_CHECK_HEADERS(HEADERS...)- ищет в системе заголовки, и для каждого найденного заголовка определяет дефайн#define HAVE_HEADER_HAC_CHECK_HEADER(HEADER, [ACT-IF-FOUND], [ACT-IF-NOT])- ...
Макросы для определения выходных файлов
AC_CONFIG_HEADERS(HEADERS...)- для каждогоHEADER.inгенерируется свойHEADER. Здесь всегда нужно использовать только одинHEADER, кроме случаев, когда вы реально чётко понимаете, зачем вам нужно несколько заголовков. В выходных заголовках буду дефайны, определённые сAC_DEFINEAC_CONFIG_FILES(FILES...)- для всехFILE.inгенерируетFILE. В этих файлах будут определения, заданныеAC_SUBST. Те самыеFILE.inбудет генерироватьAutomakeиз соответствующихFILE.am. Как видите, здесь записаны именноFILE, a неMakefile, потому что разрешается с помощью этой команды обрабатывать не толькоMakefile.
Использование кастомных .in файлов
Пример с кастомным скриптом. В AC_CONFIG_FILES правило для его сборки будет записываться как:
AC_CONFIG_FILES([Makefile src/Makefile script.sh:script.in])
Сам script.in:
#!/bin/sh
SED='@SED@'
TAR='@TAR@'
d=$1; shift; mkdir "$d";
for f; do
"$SED" 's/#.*//' "$f" > "$d/$f"
done
"$TAR" cf "$d.tar" "$d"
Из этого файла скрипт config (а точнее config.stats) сделает следующее:
#!/bin/sh
SED=’/usr/xpg4/bin/sed’
TAR=’/usr/bin/tar’
d=$1; shift; mkdir "$d"
for f; do
"$SED" 's/#.*//' "$f" >"$d/$f"
done
"$TAR" cf "$d.tar" "$d"
В Makefile.in тоже используются такие плейсхолдеры (@SED), но Automake для них просто добавляет определение нужной переменной, поэтому в Makefile.in можно спокойной использовать нужное значение (например, через $(XYZ)).
Использование Automake
Automake позволяет создавать портируемые Makefile-ы, которые соответствуют стандарту GNU Coding Standard.
autoamke создаёт сложные Makefile.in на основе простых Makefile.am. Вообще, Makefile.in можно считать просто внутренней сторонней информацией automake.
Файлы Makefile.am в принципе используют то же синтаксис, что и обычные Makefile-ы, но в основном они содержать только определения переменных.
automakeсоздаёт правила сборки из определений этих переменных- при желании, можно задать дополнительные
Makefile-правила вMakefile.am- они буду сохранены в результирующемMakefileфайле.
Определение целей сборки в Makefile.am
where_PRIMARY = targets ...
_PRIMARY:targetsдолжны быть собраны как:_PROGRAMS_LIBRARIES_LTLIBRARIES(Libtool libraries)_HEADERS_SCRIPTS_DATA
where:targetsдолжны быть установлены в:bin_$(bindir)lib_$(libdir)- ... (вспоминаем файловую иерархию)
-
custom_$(customdir)- можно использовать кастомную библиотеку
-
noinst_- не установлены
-
check_- собраны с помощью `make check
Определение исходников в Makefile.am
bin_PROGRAMS = foo run-me
foo_SOURCES = foo.c foo.h print.c print.h
run_me_SOURCES = run.c run.h print.c
- Все символы, которые не являются буквой/цифрой, в
automakeзаменяются на_- см.run_me_SOURCES - В списке исходников мы указываем заголовочные файлы, хотя не должны этого делать (они же включаются препроцессором). Заголовочные файлы указываются для того, чтобы они были в дальнейшем распространены
automake. - Как видим, можно использовать одни и те же исходники в нескольких целях сборки
- Компилятор и линковщик определяются на основе разрешений файлов
Библиотеки
Для сборки библиотек с использованием automake необходимо:
- Определить макрос
AC_PROG_RANLIBвconfigure.ac - Описать правило сборки библиотеки в
Makefile.am:
lib_LIBRARIES = libfoo.a libbar.a
libfoo_a_SOURCES = foo.c privfoo.h
libbar_a_SOURCES = bar.c privbar.h
include_HEADERS = foo.h bar.h
- Библиотеки будут установлены в
$(libdir) - Названия библиотек должны соответствовать паттерну
lib*.a - Общие заголовки могут быть установлены в
$(includedir) - Приватные заголовки не устанавливаются, в отличие от остальных
Устройство директорий
- На одну директорию должен быть максимум один
Makefile(можно в принципе и 0) - Все вложенные
Makefileдолжны быть объявлены вconfigure.ac(как пример -Hello World) makeзапускается в корневой папке- В файлах
Makefile.amдолжен чётко задаваться порядок, в котором вызываются вложенныеMakefile.amдля дочерних директорий:
SUBDIRS = dir_a dir_b
Если чётко в SUBDIRS не указать текущую папку, она (текущий Makefile.am) будет обработан в конце, после всех объявленных папок (dir_a, dir_b).
Пример чёткого обозначения порядка каталогов:
SUBDIRS = dir_a . dir_b
Текущий Makefile.am будет обработан после обработки вложенных Makefile.am в папке dir_a.
Подключение локальных библиотек
Как было описано ранее, скрипт configure в конечном итоге не обязательно будет запускаться из корневой директории. Типичный сценарий:
mkdir build && cd build
../configure
Поэтому это нужно учитывать и при написании Makefile-ов. Например, вместо написания -Idir, лучше использовать предпопределённую переменную -I$(srcdir).
Библиотеки для упрощения сборки
Можно определять библиотеки, которые будут нужны только в рамках процесса сборки программы - как какой-то отдельный модуль в выходном проекте они будут не нужны.
noinst_LIBRARIES = libcompat.a
libcompat_a_SOURCES = xalloc.c xalloc.h
Здесь библиотека libcompat.a используется только во время сборки пакета:
LDADD = ../lib/libcompat.a
AM_CPPFLAGS = -I$(srcdir)/../lib
bin_PROGRAMS = foo run-me
foo_SOURCES = foo.c foo.h print.c print.h
run_me_SOURCES = run.c run.h print.c
run_me_LDADD = ../lib/libcompat.a
run_me_CPPFLAGS = -I$(srcdir)/../lib
LDADDдобавляется при линковке всех программAM_CPPFLAGSсодержит дополнительные флаги для препроцессора
Флаги для сборки целей
target_CFLAGS- дополнительные флаги для компилятораCtarget_CPPFLAGS- дополнительные флаги препроцессора (-I,-D)target_LDADD- дополнительные объекты для линковки (-l,-L) (еслиtarget- это программа)target_LIBADD- то же, что иtarget_LDADD, только дляtarget-а библиотекиtarget_LDFLAGS- дополнительные флаги для линковщика
Для имён библиотек, объявленных внутри пакета, лучше использовать прямой путь до файла, а -l и -L использовать только для внешних зависимостей.
Также не стоит забывать про возможность использовать переменные с библиотеками из макросов Autoconf (AC_CHECK_LIB)
Что попадает в пакет (дистрибутив) (tar.gz)
- Всех исходники, объявленные через
_SOURCES - Все заголовочные файлы, объявленные через
_HEADERS - Все скрипты, объявленные через
_SCRIPTS - Все файлы с данными, объявленные через
_DATA - ...
- Стандартные файлы, включаемые в проект по стандартам
GNU Coding Conventions(NEWS,AUTHORS,CONTRIBUTING, ...) - Дополнительные файлы или директории, объявленные напрямую через
EXTRA_DIS
Условные выражения
Условная сборка программ:
bin_PROGRAMS = foo
if WANT_BAR
bin_PROGRAMS += bar
endif
foo_SOURCES = foo.c
bar_SOURCES = bar.c
Условное подключение исходников:
bin_PROGRAMS = foo
foo_SOURCES = foo.c
if WANT_BAR
foo_SOURCES += bar.c
endif
Что здесь происходит?
barбудет собран, только еслиWANT_BAR = truebar.oбудет слинкован вfooеслиWANT_BAR = true- Во всех случаях foo.c и bar.c будут добавлены в дистрибутив независимо от значения
WANT_BAR WANT_BARдолжен быть объявлен вconfigure.ac
Объявление условных параметров в configure.ac
AM_CONDITIONAL(NAME, CONDITION). CONDITION - это инструкция для оболочки командной строки. Если она выполняется успешно, условный парамер NAME будет включен
Расширение правил сборки Automake
- Содержимое
Makefile.amкопируется вMakefile.inпочти дословно automakeдобавляет новые правила сборки и новые переменные вMakefile.in, чтобы реализовать функционал переменных, вручную объявленных вами- Небольшое изменение исходного
Makefile.amкода производится для того, чтобы такие вещи, как, например, условные выражения, или+=, работали на разных платформах. - Не является плохой практикой объявлять свои собственные правила в
Makefile.am. Например, для поддержания качества кода (make style-check). - Не является плохой практикой объявлять переменные, которые не имеют для
automakeникакого смысла. Например, для использования в кастомных правилах. - Остерегайтесь внутренних конфликтов automake!. Ваши вручную определённые имена или правила сборки могут конфликтовать с уже существующими. Такое поведение можно избежать, используя флаг
-Wall
Источники
- A. Duret-Lutz - Using GNU Autotools - May 16, 2010